
Fooocus|简单高效堪比Midjourney的免费开源AI绘画
Fooocus是一个图像生成软件。是对Stable Diffusion和Midjourney设计的一种结合:
- 从Stable Diffusion中学到,该软件是离线的、开源的,而且是免费的。
- 从Midjourney中学到,不需要手动调整,用户只需专注于提示和图像。
Fooocus已经包含并自动化了许多内部优化和质量改进。用户可以忘记所有那些复杂的技术参数,只需享受人与计算机之间的互动,以“探索新的思维媒介,拓展人类的想象力”。
Fooocus简化了安装过程。在点击“下载”和生成第一张图像之间,所需的鼠标点击次数严格限制在3次以下。最低GPU内存要求为4GB(Nvidia)。
Fooocus还为高级用户开发了许多“仅限Fooocus”的功能,以获得完美的结果。
项目仓库
GitHub:lllyasviel/Fooocus
软件安装
Windows|自行安装
注意:在安装过程中,你可能即便开启了魔法上网也无法下载一些编程依赖库,关于魔法上网的相关配置问题不方便在站内讲解,请自行查看【魔法上网】的教程内容。
如果你想手动安装部署,那么可以前往Github手动下载该软件压缩包,解压之后你将会看到一个名为run.bat的可执行文件,运行后将会自动下载相关模型,然后自动在浏览器中启动绘画界面。
如果你想通过网盘下载软件安装包,自己手动下载模型,那么本站也为你提供了最新版本的网盘下载地址【点此下载】。
如果你想手动下载模型,那么通过以下方式手动下载并移动至Fooocus的相应目录中。
- 下载
sd_xl_base_1.0_0.9vae.safetensors文件移动至.\Fooocus\models\checkpoints目录内。 - 下载
sd_xl_refiner_1.0_0.9vae.safetensors文件移动至.\Fooocus\models\checkpoints目录内。
Windows|一键启动
本站已经为你打包好了一键启动版本,可以直接解压使用,并且贴心的为你添加了三种启动方式。
在你下载并解压该文件后,你将会看到以下三个Bat批处理文件。
- run – 本机.bat
- 仅在当前电脑中使用,可以直接运行此脚本,将会自动打开浏览器。
- run – 公网.bat
- 如果你希望部署在公网中,可以让其它人通过网络访问,可以使用此方式启动。
- run – 局域网.bat
- 如果你希望在当前局域网中的其它设备(比如平板或手机)可以使用绘画功能,可以通过此方式启动。
Linux
如果你想使用Linux系统运行该程序,可以通过如下方式安装,因为本站主要针对Windows用户,所以Linux部分一代而过。毕竟使用Linux系统的,应该也看的懂下面的代码如何使用。
git clone https://github.com/lllyasviel/Fooocus.git cd Fooocus conda env create -f environment.yaml conda activate fooocus pip install -r requirements_versions.txt
下载模型:
- 下载
sd_xl_base_1.0_0.9vae.safetensors文件移动至.\Fooocus\models\checkpoints目录内。 - 下载
sd_xl_refiner_1.0_0.9vae.safetensors文件移动至.\Fooocus\models\checkpoints目录内。
如果你不希望手动下载,那么在启动的时候,Fooocus将会自动下载模型:
python launch.py
或者如果您想打开远程端口,可以使用
python launch.py --listen
Mac|Windows(AMD显卡)
即将推出…
使用教程
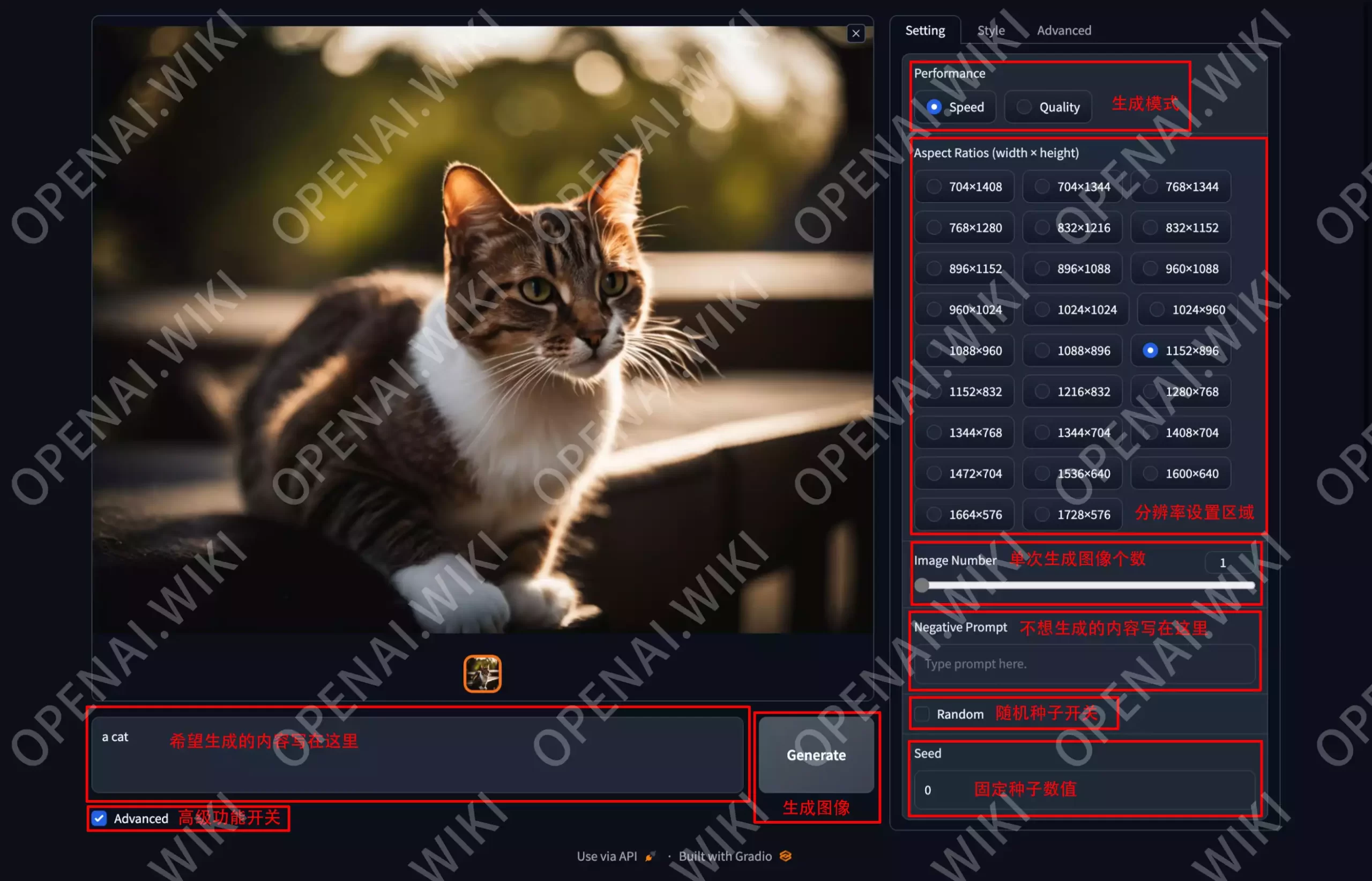
基本设置
当你已经通过软件自动启动软件时,将会自动打开浏览器,你可以通过以下方式去设置,非常简洁。
风格设置
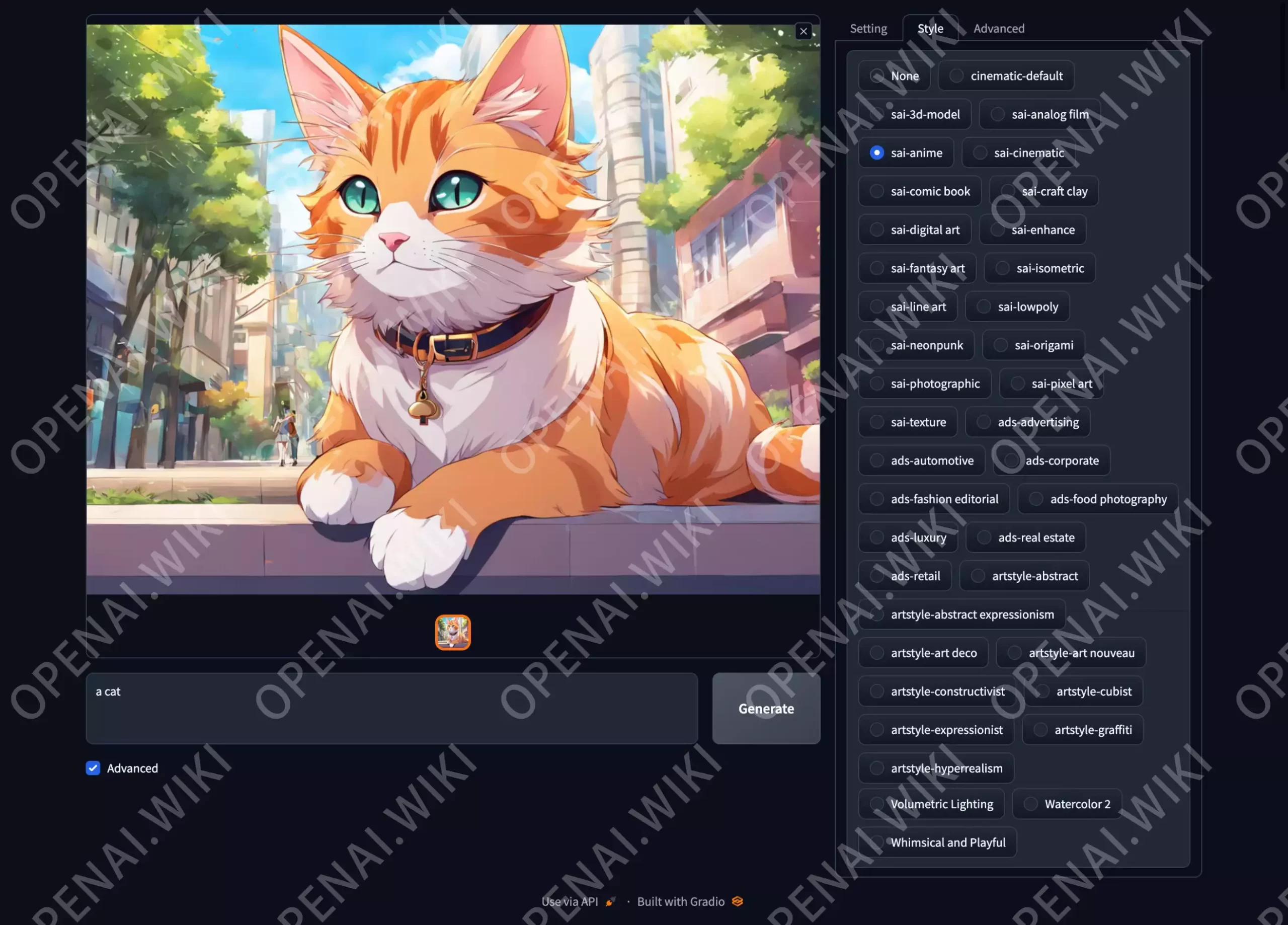
该软件内置了非常多风格,你可以快速生成效果极佳的内容,如果你对SD的Prompt复杂提示词和设置感到迷茫,那么这款软件将会非常适合你。
站长仅选择风格为动漫,其它全部未变更的情况下,生成的效果就已经非常不错了。
注意:因为预设实再太多,所以站长这张截图中已经裁剪下去大部分预设,并没有全部截图,避免图像模糊,所以你在使用时会看到比下图更多的风格可以选择。
高级设置
此部分设置可以独立设置基础模型以及LoRA模型,还可以进行模型权重调节以及融合。
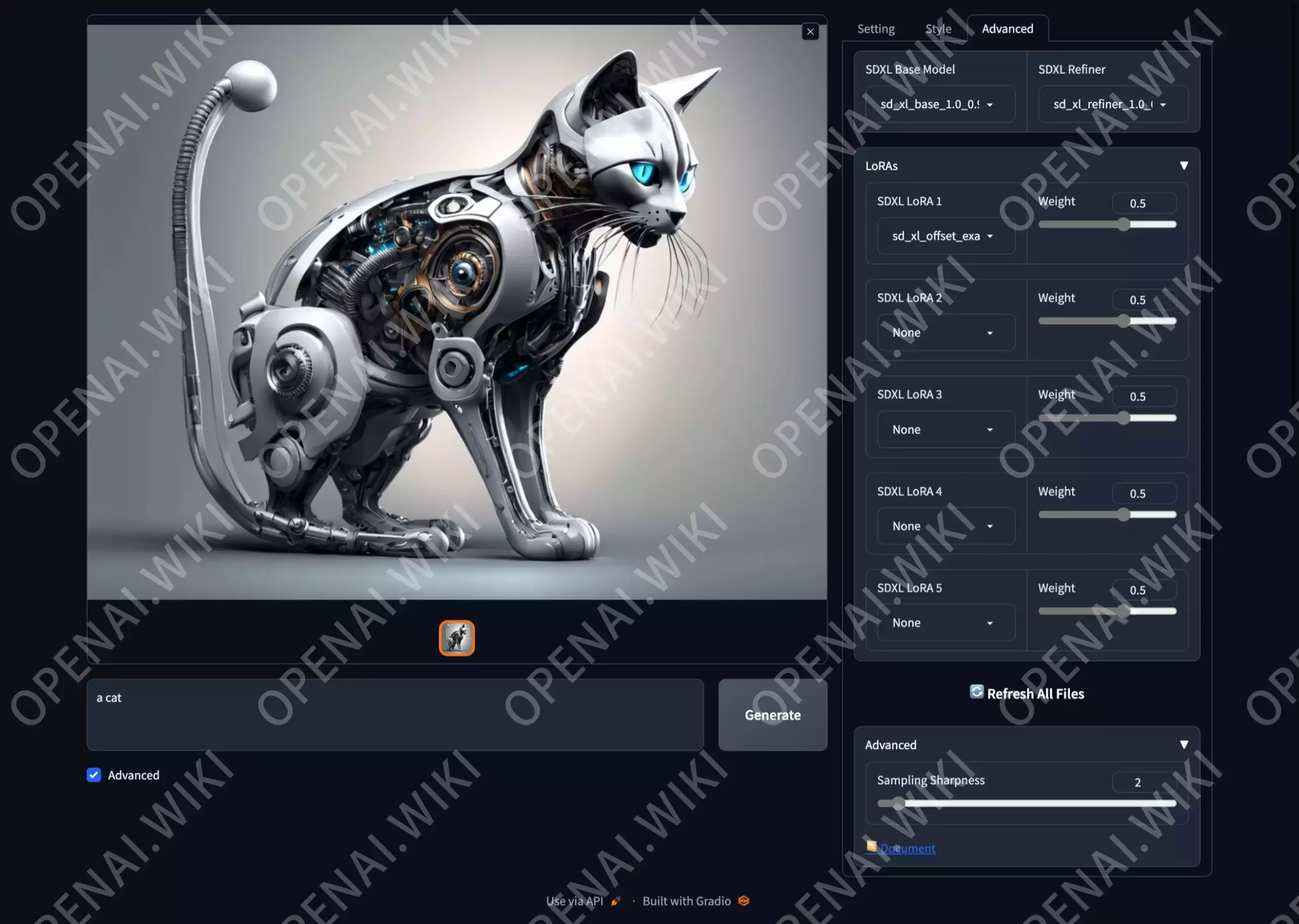
这里有一个比较重要的参数单独讲解一下,那就是右下角的Sampling Sharpness功能。
Sampling Sharpness翻译为中文可以理解为采样锐度
采样锐度是由Fooocus开发的最终解决方案,用于解决SDXL有时会生成过于平滑的图像或塑料外观图像的问题。
与Automatic1111的cfg-scale等其他参数不同,此锐度永远不会影响图像的全局结构,因此易于控制,而且不会弄乱图像(相同种子)。
这个选项相对较为适度,因此图像不太可能被过度处理。
当SDXL的结果过于平滑时,此选项可以解决90%的问题。
以下是关于锐度的示例,大家可以对比一下效果。
提示词:a girl
风格:sai-neonpunk(赛博朋克)
种子:0




隐藏技巧清单
以下这些功能已经内置在软件中,用户不需要对这些进行任何操作。
- 本地refiner交换在单个k采样器中。优势在于refiner模型现在可以重复使用基础模型从k采样中收集的动量(或ODE的历史参数),以实现更连贯的采样。在Automatic1111的高分辨率修复和ComfyUI的节点系统中,基础模型和refiner使用两个独立的k采样器,这意味着动量在很大程度上被浪费,采样的连续性被破坏。Fooocus使用其自己先进的k-diffusion采样,确保在refiner设置中实现无缝、本地和连续的交换。(2023年8月13日更新:实际上,我几天前已经与Automatic1111讨论过这个问题,似乎“在单个k采样器中本地交换refiner”已经合并到了WebUI的开发分支中。太好了!)
- 负ADM引导。由于XL Base的最高分辨率级别没有交叉注意力,XL的最高分辨率级别的正负信号在CFG采样过程中无法获得足够的对比度,导致在某些情况下结果看起来有点塑料或过于平滑。幸运的是,由于XL的最高分辨率级别仍然是基于图像纵横比(ADM)进行条件化的,我们可以修改正/负方向上的adm,以补偿最高分辨率级别中CFG对比度的不足。(2023年8月16日更新,IOS App Drawing Things将支持负ADM引导。太好了!)
- 我们实现了“通过自注意力引导改进扩散模型样本质量的第5.1节”的一个经过精心调整的变体。权重设置得非常低,但这是Fooocus的最终保证,以确保XL永远不会产生过于平滑或塑料的外观(示例在这里)。这几乎可以消除XL偶尔产生过于平滑的结果的所有情况,即使有负ADM引导。(2023年8月18日更新,SAG的高斯核已更改为各向异性核,以获得更好的结构保持和更少的伪影。)
- 我们稍微修改了样式模板,并添加了“cinematic-default”。
- 我们测试了“sd_xl_offset_example-lora_1.0.safetensors”,似乎当lora权重低于0.5时,结果总是优于没有lora的XL。
- 采样器的参数经过精心调整。
- 由于XL为生成分辨率使用位置编码,几个固定分辨率生成的图像看起来比来自任意分辨率的图像要好一些(因为位置编码在处理训练中看不见的整数时不太好)。这表明UI中的分辨率可能是硬编码的,以获得最佳结果。
- 为两个不同的文本编码器分别设置提示似乎是不必要的。为基础模型和refiner分别设置提示可能会起作用,但效果是随机的,我们不打算实现这个功能。
- DPM系列似乎非常适合XL,因为XL有时会生成过于平滑的纹理,但DPM系列有时会生成过于密集的细节纹理。它们的联合效果看起来中性且吸引人的感知。
虚拟化技术
请注意,最低要求是4GB Nvidia GPU内存(4GB VRAM)和8GB系统内存(8GB RAM)。这需要使用Microsoft的虚拟交换技术,在大多数情况下会自动启用您的Windows安装,因此您通常不需要做任何操作。但是,如果您不确定,或者如果您手动关闭了它(谁会真的这样做呢?),或者如果您看到任何“RuntimeError: CPUAllocator”,您可以在此处启用它:
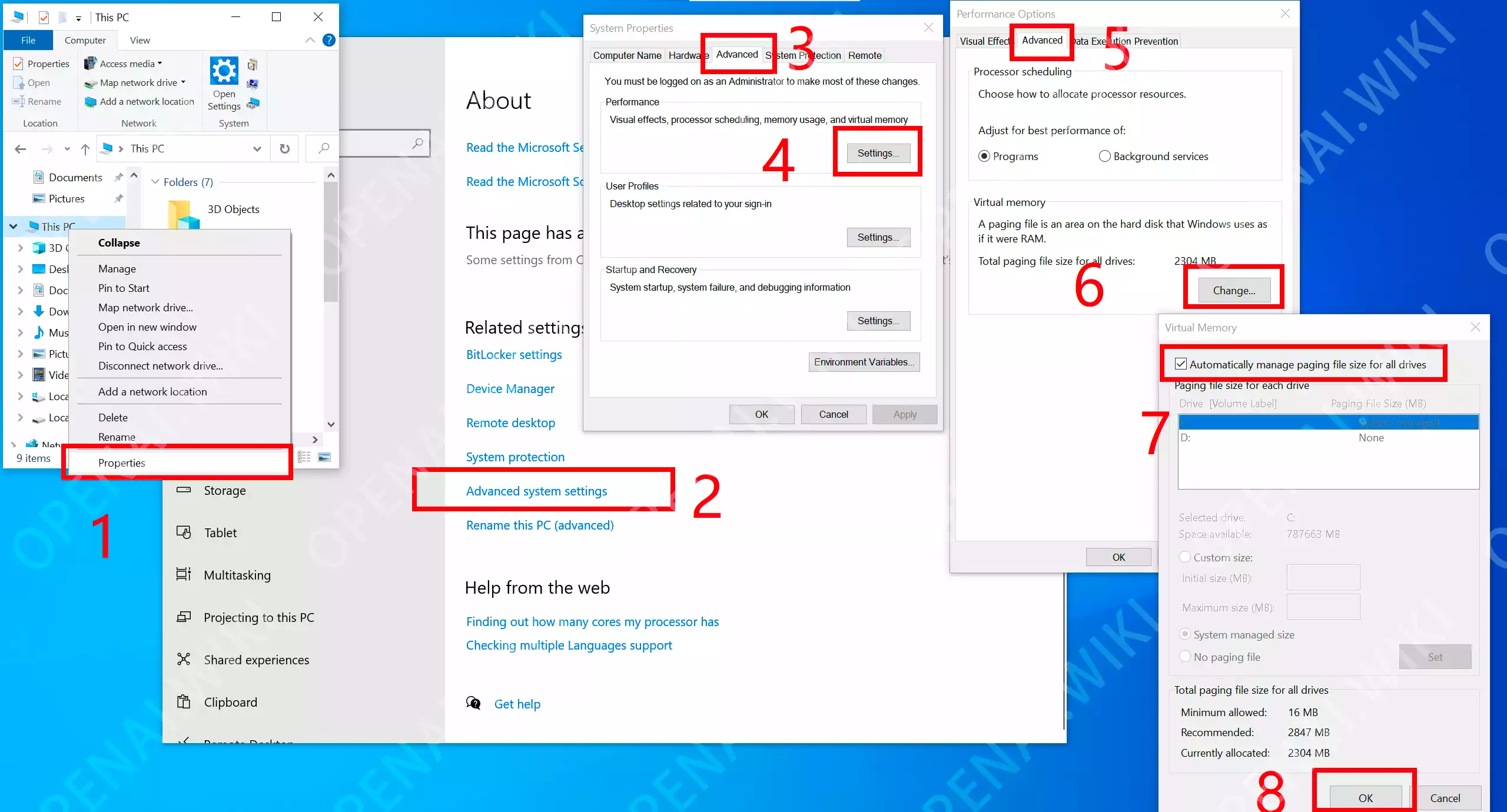
如果您仍然看到“RuntimeError:CPU Allocator”,请确保每个硬盘驱动器上至少有 40GB 可用空间!
更新日志
Fooocus版本更新暂时暂停,以适应AUTOMATIC1111 sd-webui 1.6.X的开发,同时一些功能也将作为WebUI扩展实现。
- 1.0.40
- 将行为恢复到1.0.36版本(refiner步骤)。1.0.36版本过于完美和典型;超越1.0.36版本几乎是不可能的。
- 1.0.39
- 回退了1.0.37版本和1.0.38版本之间的不稳定更改。
- 将refiner步骤增加到采样步骤的一半。
- 1.0.36
- 将高斯核函数更改为各向异性核函数。
- 1.0.34
- 恢复了随机种子设置。
- 1.0.33
- 在删除图像时隐藏日志中的条目。
- 1.0.32
- 添加了Fooocus私有日志。
- 1.0.31
- 修复了拼写错误和用户界面。
- 1.0.29
- 为未来的开发添加了“高级->高级->高级”块。
- 1.0.29
- 修复了1.0.28版本中的过度处理问题。
- 1.0.28
- 实现了SAG(Self-Attention Guidance)。
- 1.0.27
- 在文本框CSS中修复了一个小问题。
- 1.0.25
- 支持sys.argv参数–listen、–share和–port。
- 1.0.24
- 增加了更高的输入文本框。
- 1.0.23
- 在UI启动后的Linux上添加了一些提示,以便用户知道应用程序没有失败。
- 1.0.20
- 支持Linux系统。
- 1.0.20
- 加快了文本编码器的速度。
- 重新编写UI以使用异步代码:(1)以实现更快的启动,和(2)以实现更好的实时预览。
- 删除了对OpenCV的依赖。
- 计划尽快支持Linux系统。
- 1.0.19
- 解锁以允许更改模型。
- 1.0.17
- 将默认模型更改为SDXL-1.0-vae-0.9。(这意味着模型将会被重新下载,但我们应该尽早执行此操作,以便所有新用户只需下载一次。对于使用1.0.0版本的用户,我们表示真诚的歉意。但坦率地说,
- 虑到该项目公开发布还不到24小时,这并不算太晚——如果已经过去了一周,我们会更倾向于使用更轻量级的方法来更新。)
- 1.0.16
- 为保存用户结果创建了“Fooocus/outputs”文件夹。
- 在预览失败时忽略了cv2错误。
- 在自述文件中提到了未来对AMD支持。
- 创建了此更新日志。
- 1.0.15
- 正式公开发布。
- 1.0.0
- 初始版本。
总结
该软件相比于SD虽然缺少很多高级自定义功能,但是使用方便且轻量,对于非重度人员来讲完全够用,最主要的是方便,也不会报错,参数一目了然。
而且内置的预设多达上百种,命名明了,极为推荐。


今天部号体验了下,效果非常惊艳!不愧是SD XL,出图质量高,唯一的缺点是加载模型太慢(3分钟左右),还会有部分报错,我做了如下修改
1.comfy/sample.py
第67行增加
def load_additional_models(positive, negative, dtype):
get_additional_models(positive, negative, dtype)
2.comfy/sample.py
cleanup_additional_models增加
if models is not None:
3.链接comfyui的nodes.py folder_paths latent_preview.py到venv
@HawkingEye 加载模型的时间的确非常久,但是站长下载的位置位置在C盘运行项目时,因为C盘是SSD,所以加载速度极快。但当站长打包后移动到其它非固态盘符下运行时,模型的速度的确成指数下降。
关于你所给出的报错,我这里并没有提示,所以没办法复现,但感谢给出解决方法。
为什么我这边打开之后,界面没有预设和参数调整的ui?
@dan 哦看到了 是翻译插件遮挡住了那个按钮 无奈