

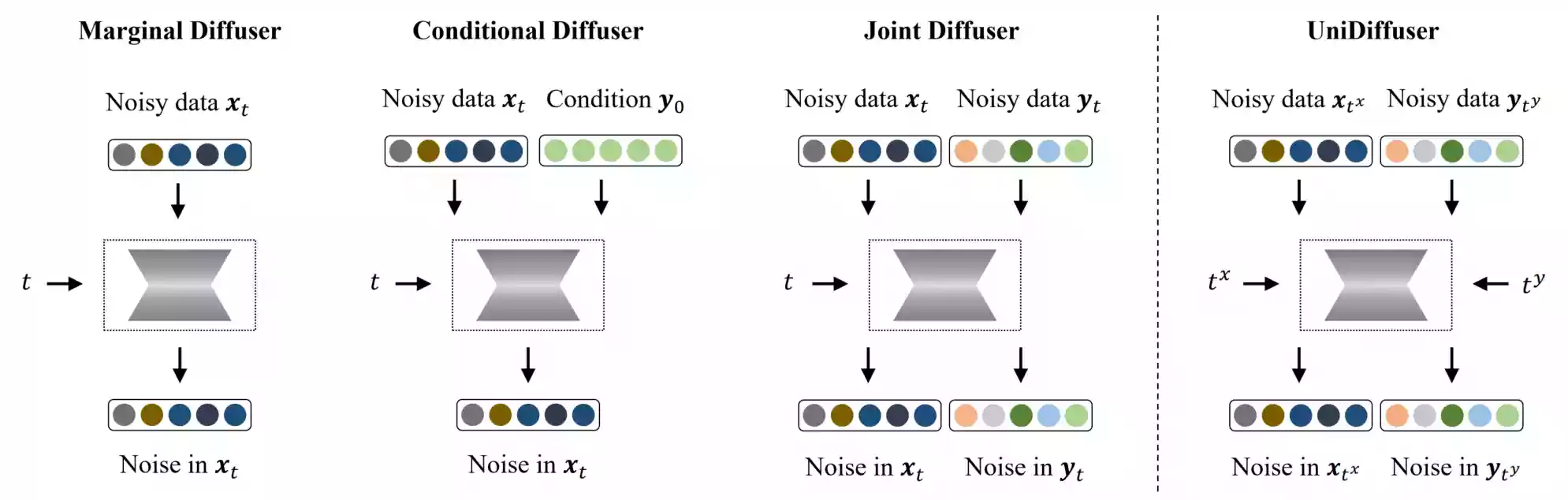
UniDiffuser是一个统一的扩散框架,用于在一个模型中拟合与一组多模态数据相关的所有分布。它的关键是:学习边缘、条件和联合分布的扩散模型可以统一为预测扰动数据中的噪声,其中不同模态的扰动级别(即时间步长)可以不同。受到这个统一视角的启发,UniDiffuser通过对原始扩散模型进行最小修改,同时扰动所有模态的数据,输入不同模态的单独时间步长,预测所有模态的噪声,学习所有分布。UniDiffuser由一个用于处理不同模态输入类型的扩散模型变压器参数化。在大规模配对的图像文本数据上实现,UniDiffuser能够通过设置适当的时间步长执行图像、文本、文本到图像、图像到文本和图像文本配对生成,而不需要额外的开销。特别地,UniDiffuser能够在所有任务中产生感知上逼真的样本,其定量结果(例如FID和CLIP分数)不仅优于现有的通用模型,而且在代表性任务(例如文本到图像生成)中与定制模型(例如稳定扩散和DALL-E 2)相媲美。
GitHub
项目开源地址:thu-ml/unidiffuser
部署教程
如果您是初学者,对于命令行不太理解,那么请按下键盘上的Win键+R键后,在弹出的新窗口内输入CMD并按下回车,打开CMD窗口,按顺序执行如下的每一条命令。
首先我们需要确认一个工作目录,用来存放UniDiffuser的相关环境依赖文件。本站所选择的目录为D盘的根目录下openai.wiki文件夹,完整路径为:D:\openai.wiki。
检测D盘目录下是否在openai.wiki文件夹,如果没有openai.wiki
if not exist D:\openai.wiki mkdir D:\openai.wiki
拉取Github仓库文件夹,将下载至openai.wiki文件夹。
git clone https://github.com/thu-ml/unidiffuser.git
注意:如果您无法完成此步骤,执行后报错或者无法下载,可以下载该文件将其解压至D:\openai.wiki即可。
强制切换工作路径为D盘的openai.wiki\unidiffuser文件夹。
cd /d D:\openai.wiki\unidiffuser
环境安装
为不影响电脑中的现有环境,请一定要安装Conda,如果您不知道什么是Conda,或者未安装过Conda,请参考如下文章,安装部署Conda之后再继续以下步骤。
在CMD中执行下面的命令行,创建Conda虚拟环境至该项目的目录中,方便日后重装系统也能够正常使用,无需重新部署环境。
conda create -p D:\openai.wiki\unidiffuser\ENV python=3.9
执行完成上面的命令之后,将会在CMD窗口中看到Proceed ([y]/n)?提示,我们直接按下回车即可。
初始化Conda环境,避免后续可能报错。
conda init cmd.exe
激活已创建的Conda环境,这样我们可以将我们后续所需要的所有环境依赖都安装至此环境下。
conda activate D:\openai.wiki\unidiffuser\ENV
执行如下命令,安装torch依赖。
pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/cu116
执行如下命令,安装transformers等依赖库。
pip install accelerate==0.12.0 absl-py ml_collections einops ftfy==6.1.1 transformers==4.23.1
执行如下命令,安装CLIP依赖库。
pip install -e git+https://github.com/openai/CLIP.git@main#egg=clip
注意:该库不一定非要安装,但是推荐安装,因为这会大大加快出图速度。执行如下命令,安装xformers依赖库。
pip install -U xformers
pip install -U --pre triton
模型介绍
模型描述
UniDiffuser使用变种的transformer,称为U-ViT,来参数化联合噪声预测网络。其他组件作为不同模态的编码器和解码器,包括从Stable Diffusion预训练的图像自编码器、预训练的图像ViT-B/32 CLIP编码器、预训练的文本ViT-L CLIP编码器以及我们自己微调的GPT-2文本解码器。
我们提供两个版本的UniDiffuser,其中包含1B参数的U-ViT,并且可以在至少有10GB内存的GPU上运行。它们可以从Hugging Face或者本站提供的网盘内下载:
- UniDiffuser-v0:该版本在512×512分辨率的LAION-5B上进行训练,其中包含文本-图像对的噪声网络数据。
- UniDiffuser-v1:该版本从UniDiffuser-v0中恢复,并进一步使用一组较少噪声的内部文本-图像对进行训练。在训练期间,它使用标志来区分网络数据和内部数据。
这两个链接都包含三个文件:
- autoencoder_kl.pth是从Stable Diffusion转换的图像自编码器的权重。
- caption_decoder.pth是微调的GPT-2文本解码器的权重。
- uvit_v0.pth或uvit_v1.pth是UniDiffuser-v0或UniDiffuser-v1的U-ViT权重。
请注意,UniDiffuser-v0和UniDiffuser-v1共享相同的autoencoder_kl.pth和caption_decoder.pth。您只需要下载它们一次。至于其他组件,它们将自动下载。
下载完成后,创建一个名为models的新文件夹,并将所有预训练模型放入该文件夹中,如下所示:
├── models │ └── autoencoder_kl.pth │ └── caption_decoder.pth │ └── uvit_v0.pth or uvit_v1.pth
官网下载
官方下载地址:https://huggingface.co/thu-ml
将下载后的所有文件放置在项目目录D:\openai.wiki\unidiffuser\models内,注意目录名称的大小写和结构,按此结构放置模型可以不用修改任何配置文件。
网盘下载
本站已整理好模型相关路径,下载该压缩包之后,解压该文件将会得到一个名为models的文件夹,将其移动至D:\openai.wiki\models目录下即可,无需修改任何文件。
使用教程
疑难解答
按道理来说,我们现在就应该已经可以正常使用UniDiffuser进行创作啦。
但是!本站经过测试,仍然无法正常使用的,我们还需要一些其它步骤,不然必会报错。
Create autoencoder with scale_factor=0.18215
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
D:\openai.wiki\unidiffuser\ENV\lib\site-packages\torch\amp\autocast_mode.py:204: UserWarning: User provided device_type of 'cuda', but CUDA is not available. Disabling
warnings.warn('User provided device_type of \'cuda\', but CUDA is not available. Disabling')
2023-04-08 12:14:41,382 - sample_multi_v1.py - sample_steps: 50
scale: 7.0
t2i_cfg_mode: true_uncond
2023-04-08 12:14:41,382 - sample_multi_v1.py - N=1000
D:\openai.wiki\unidiffuser\ENV\lib\site-packages\torch\utils\checkpoint.py:31: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn("None of the inputs have requires_grad=True. Gradients will be None")
首先是创建输出目录,在UniDiffuser项目目录下创建一个名为out的文件夹,也可以通过执行如下命令行来自动创建。
if not exist D:\openai.wiki\unidiffuser\out mkdir D:\openai.wiki\unidiffuser\out
PyTorch
在安装PyTorch之前,您需要先前往官网(PyTorch)查看自己应该安装哪个版本。
请您像下图一样按顺序选择即可,依次选择Stable->Windows->Conda->Python->CUDA 11.8。
其中的Stable其实就是稳定版的PyTorch,Preview(Nightly)是每天更新的预览测试版,可能存在未知Bug,所以最好选择Stable版本。
如果您看到的不是CUDA 11.8,而是CUDA 11.9或更高的版本也没关系,只要前缀是CUDA即可。
在您按顺序选择好之后,复制下面的<Run this Command>的内容即可,例如本站所得到的为:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
将您所复制的代码直接粘贴至CMD窗口内执行,此时将会自动安装PyTorch和对应版本的CUDA,因为PyTorch比较大,所以等待时间会比较长,请不要中断该操作。
注意:一定要复制你自己得到的,尽量不要直接使用本站所给出的示例命令行!

执行如下命令,安装chardet依赖库。
pip install chardet
执行如下命令,更新相关依赖库。
pip install --upgrade charset-normalizer
至此,我们已经解决了所有可能导致无法生成图片的问题。
图像生成
如果您重新开机或已经关闭了运行的窗口,那么您就需要重新执行一次以下两行命令行,用来激活环境。
conda activate D:\openai.wiki\unidiffuser\ENV
cd /d D:\openai.wiki\unidiffuser
我们建议使用UniDiffuser-v1模型,可以获得更好的性能。默认情况下,生成创作后的图像将放入out目录中。
文本到图像生成
在CMD窗口内执行如下命令,首先是调用名为sample_multi_v1.py的Python脚本,模式为t2i(txt to image|文本到图像),Prompt提示词为an elephant under the sea,中文译为海底的大象。
python sample_multi_v1.py --mode=t2i --prompt="an elephant under the sea"

图像到文本生成
在UniDiffuser的项目目录下,已经存在了一个assets文件夹,里面官方预置了一张名为space的图片。
我们执行图像到文本的推理命令行,尝试获取该图片的描述。

python sample_multi_v1.py --mode=i2t --img=assets/space.jpg
执行如上命令后,将会在D:\openai.wiki\unidiffuser\out\i2t目录下自动创建一个名为i2t.txt的文本文档,里面的内容即是对该图像的描述,文档内容如下。
An astronaut flying in space with the Earth in the background
翻译为中文为:一名宇航员在太空中飞行,背景是地球。
联合生成
python sample_multi_v1.py --mode=joint

图像生成
python sample_multi_v1.py --mode=i

文本生成
python sample_multi_v1.py --mode=t
输出内容为:A man in white is working in a gym
图像变体
python sample_multi_v1.py --mode=i2t2i --img=assets/space.jpg

文本变体
python sample_multi_v1.py --mode=t2i2t --prompt="an elephant under the sea"
输出内容为:An elephant swimming in the ocean in an aquarium
其它参数
我们在下面提供所有支持的参数
--mode 生成类型,可选t2i / i2t / joint / i / t / i2t2i / t2i2t
t2i: 文本生成图片
i2t: 图片生成文本
joint: 文本和图片联合生成
i: 仅生成图片
t: 仅生成文本
i2t2i: 图片变体,先生成文本,再生成图片
t2i2t: 文本变体,先生成图片,再生成文本
--prompt 文本生成图片和文本变体的提示语
--img 图片生成文本和图片变体的图片路径
--n_samples 要生成的样本数量,默认为1
--nrow 每行网格中显示的图像数量,默认为4
--output_path 将结果写入的目录,默认为out
--config.seed 随机种子,默认为1234
--config.sample.sample_steps dpm_solver采样步骤的数量,默认为50
--config.sample.scale 无分类器的条件生成指导,数值越大,指导越弱,默认为7
--config.sample.t2i_cfg_mode 用于文本生成图片,可选true_uncond / empty_token,默认为true_uncond
true_uncond: 使用UniDiffuser的无条件模型进行无分类器指导
empty_token: 使用空字符串进行无分类器指导
--config.data_type 0或1中的一个,用于UniDiffuser-v1,默认为1
0: 对应训练时的WebDataset
1: 对应训练时的内部数据
UniDiffuser-v0 的推理命令与 UniDiffuser-v1 基本相同,只需要更改为 。例如:sample_multi_v1.pysample_multi_v0.py
python sample_multi_v0.py --mode=t2i --prompt="an elephant under the sea"
总结
整体感觉不如Stable Diffusion,效果很一般,而且官方并没有集成GUI界面,增加了使用难度。


评论 (0)