

VToonify|图片视频动漫风格化
生成高质量艺术肖像视频是计算机图形学和计算机视觉中一项重要且令人向往的任务。虽然基于强大的 StyleGAN 模型构建的一系列成功的肖像图像卡通化模型已经被提出,但这些面向图像的方法在应用于视频时存在明显的局限性,如固定帧大小、需要面部对齐、缺失非面部细节和时间不一致性等。在本文中,我们通过引入一种新颖的 VToonify 框架来研究具有挑战性的可控高分辨率肖像视频风格转移。具体来说,VToonify 利用 StyleGAN 的中分辨率和高分辨率层来渲染高质量的艺术肖像,基于编码器提取的多尺度内容特征来更好地保留帧细节。所得到的完全卷积架构接受大小可变的视频中的非对齐面部作为输入,为输出的自然动作提供了完整的面部区域。我们的框架与现有的基于 StyleGAN 的图像卡通化模型兼容,可将它们扩展到视频卡通化,并继承这些模型的吸引人的特性,以实现对颜色和强度的灵活风格控制。本文提出了基于 Toonify 和 DualStyleGAN 的两种 VToonify 实例,分别用于基于集合和基于示例的肖像视频风格转移。广泛的实验结果表明,我们提出的 VToonify 框架在生成高质量和时间上连贯的艺术肖像视频以及灵活的风格控制方面优于现有方法。
前言
本篇教程写了差不多三天,网上关于VToonify的安装部署资料几乎为零,VToonify的官方Github中关于部署的描述也基本没有任何帮助,而且对于以下插件的安装顺序也没有描述。还有就是官方所给出的环境YAML文件无法通过Conda安装,所以想独立部署VToonify真的非常非常麻烦,请大家一定要严格按照以下顺序安装部署,不然基本必会报错,希望以下内容能给大家带来帮助。
特点
高分辨率视频(>1024,支持非对齐人脸)| 数据友好(无需真实训练数据)| 风格控制
预训练模型
图像/视频卡通化的推断
| Backbone | 模型 | 描述 |
|---|---|---|
| DualStyleGAN | cartoon | 预训练的 VToonify-D 模型和 317 个卡通风格代码 |
| caricature | 预训练的 VToonify-D 模型和 199 个漫画风格代码 | |
| arcane | 预训练的 VToonify-D 模型和 100 个神秘风格代码 | |
| comic | 预训练的 VToonify-D 模型和 101 个漫画风格代码 | |
| pixar | 预训练的 VToonify-D 模型和 122 个皮克斯风格代码 | |
| illustration | 预训练的 VToonify-D 模型和 156 个插图风格代码 | |
| Toonify | cartoon | 预训练的 VToonify-T 模型 |
| caricature | 预训练的 VToonify-T 模型 | |
| arcane | 预训练的 VToonify-T 模型 | |
| comic | 预训练的 VToonify-T 模型 | |
| pixar | 预训练的 VToonify-T 模型 | |
| 支持模型 | ||
| encoder.pt | Pixel2style2pixel编码器,用于将真实人脸映射到 StyleGAN 的 Z+ 空间 | |
| faceparsing.pth | 来自 face-parsing.PyTorch 的用于人脸分割的 BiSeNet | |
VToonify-D 模型的名称带有后缀,以指示设置,其中
_sXXX:仅支持一个固定风格,带有此风格的索引XXX。- _s 没有:表示该模型支持基于样本的风格转移
XXX。
- _s 没有:表示该模型支持基于样本的风格转移
_dXXX:仅支持固定风格程度。XXX- _d 没有:表示该模型支持风格程度从 0 到 1
XXX。
- _d 没有:表示该模型支持风格程度从 0 到 1
_c:支持颜色转移。
GitHub
项目开源地址:williamyang1991/VToonify
部署教程
Visual Studio
下载地址:Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器 (microsoft.com)
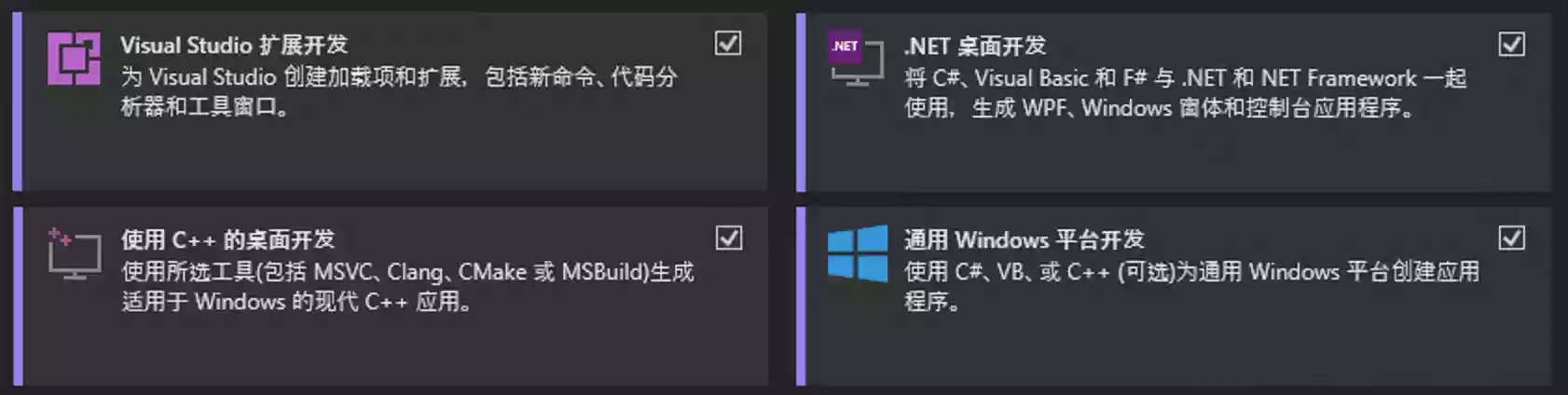
下载并安装Visual Studio 2022时,必须勾选Visual Studio 扩展开发|.Net 桌面开发|使用 C++ 的桌面开发|通过 Windows 平台开发四项,然后点击安装,等待完成即可。
环境变量
在您安装完成Visual Studio的相关组件之后,您的电脑中将会存在一个cl.exe文件,该文件所存在的路径实在无法通过脚本来确定,所以必须要您自己找到该文件的目录位置,本站的cl.exe文件存放于以下路径中,请根据自身情况定位该路径,然后将其复制。
C:\Program Files\Microsoft Visual Studio\2022\Enterprise\VC\Tools\MSVC\14.32.31326\bin\Hostx64\x64
在您得到cl.exe文件之后,将其添加到环境变量有两种办法。
- 方法1:手动打开电脑的环境变量设置,将该路径添加至用户环境变量的phth中即可。
- 方法2:以管理员方式打开CMD命令行窗口,然后执行如下代码,注意替换您自己cl所在路径。
setx PATH "%PATH%;删除此段中文替换为你所复制的路径"
例如本站应该执行如下命令:
setx PATH "%PATH%;C:\Program Files\Microsoft Visual Studio\2022\Enterprise\VC\Tools\MSVC\14.32.31326\bin\Hostx64\x64"
⚠️警告:必须要以管理员方式打开命令行窗口执行该命令,不然系统环境变量将被破坏。
CUDA
您需要在电脑中安装CUDA环境,关于CUDA的环境安装请参阅如下文章:
cuDNN
您需要在电脑中安装cuDNN环境,关于cuDNN的环境安装请参阅如下文章:
注意:必须先安装CUDN,然后再安装cuDNN,否则无法安装。
CMake
下载地址:https://cmake.org/download/
下载与自身系统版本所对应的CMake,记得勾选添加环境变量的选项,不然将无法在CMD窗口内被调用。
VToonify
如果您是初学者,对于命令行不太理解,那么请按下键盘上的Win键+R键后,在弹出的新窗口内输入CMD并按下回车,打开CMD窗口,按顺序执行如下的每一条命令。
首先我们需要确认一个工作目录,用来存放VToonify的相关文件。本站所选择的目录为D盘的根目录下openai.wiki文件夹,完整路径为:D:\openai.wiki。
1.检测D盘是否在openai.wiki,没有则创建该文件夹。
if not exist D:\openai.wiki mkdir D:\openai.wiki
2.强制切换工作路径为D盘的openai.wiki文件夹。
cd /d D:\openai.wiki
3.拉取Github仓库文件夹,将下载至openai.wiki文件夹。
git clone https://github.com/williamyang1991/VToonify.git
注意:如果您无法完成第3步,执行后报错或者无法下载,可以下载该文件将其解压至D:\openai.wiki即可。
输入以下命令会自动在<D:\openai.wiki\VToonify>文件夹内创建一个名为 <vtoonify_env> 的Python版本为3.9的虚拟环境,其中 <D:\openai.wiki\VToonify\vtoonify_env> 是您希望环境位于的位置,可根据情况自行修改相应部分:
conda create -p D:\openai.wiki\VToonify\vtoonify_env python=3.9
执行完成上面的命令之后,将会在CMD窗口中看到Proceed ([y]/n)?提示,我们直接按下回车即可。
初始化Conda环境,避免后续可能报错。
conda init cmd.exe
激活已创建的Conda环境,这样我们可以将后续所需要的所有环境依赖都安装至此环境下。
conda activate D:\openai.wiki\VToonify\vtoonify_env
一定要先安装dlib依赖库,不然必须会报错,站长在这个步骤上耽误了两天的时间。
pip install dlib
PyTorch
虽然官方没有说要安装PyTorch,但还是需要安装的,不然启动时必然会报错。
在安装PyTorch之前,您需要先前往官网(PyTorch)查看自己应该安装哪个版本。
请您像下图一样按顺序选择即可,依次选择Stable->Windows->Conda->Python->CUDA 11.8。
其中的Stable其实就是稳定版的PyTorch,Preview(Nightly)是每天更新的预览测试版,可能存在未知Bug,所以最好选择Stable版本。
如果您看到的不是CUDA 11.8,而是CUDA 11.9或更高的版本也没关系,只要前缀是CUDA即可。
在您按顺序选择好之后,复制下面的<Run this Command>的内容即可,例如本站所得到的为:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia将您所复制的代码直接粘贴至CMD窗口内执行,此时将会自动安装PyTorch和对应版本的CUDA,因为PyTorch比较大,所以等待时间会比较长,请不要中断该操作。
注意:一定要复制你自己得到的,尽量不要直接使用本站所给出的示例命令行!

以下内容,请按顺序逐条执行安装,不要一次性全部复制,不然极有可能出错。
conda install libfaiss=1.7.1 -c conda-forge conda install _libgcc_mutex=0.1 ca-certificates=2022.2.1 certifi=2021.10.8 conda install faiss=1.7.1 m2-libedit libfaiss-avx2=1.7.1 -c conda-forge conda install libffi=3.2.1 -c conda-forge conda install matplotlib-base=3.3.4 conda install python-lmdb=1.2.1 conda install setuptools conda install pip conda install pillow pip install cmake matplotlib ninja numpy opencv-python==4.5.3.56 scipy tqdm wget
模型下载
本站提供四种下载方式,任选其一即可,推荐使用123网盘下载,免登陆、免安装客户端、不限速、无广告,而且123网盘内的版本由本站提供,模型内已修复一些已知问题。
123网盘
百度云
Google云盘
Hugging Face
模型安装
将下载的模型解压至.\VToonify目录下,此时的模型文件目录结构如下:
D:\openai.wiki\VToonify\checkpoint
│ derections.npy
│ encoder.pt
│ faceparsing.pth
│ README.md
│ shape_predictor_68_face_landmarks.dat
│ shape_predictor_68_face_landmarks.dat.bz2
│ shape_predictor_68_face_landmarks.dat.bz25epbe9p1.tmp
│
├─vtoonify_d_arcane
│ exstyle_code.npy
│ vtoonify_s000_d0.5.pt
│ vtoonify_s077_d0.5.pt
│ vtoonify_s_d.pt
│ vtoonify_s_d_c.pt
│
├─vtoonify_d_caricature
│ exstyle_code.npy
│ vtoonify_s039_d.pt
│ vtoonify_s039_d0.5.pt
│ vtoonify_s068_d0.5.pt
│
├─vtoonify_d_cartoon
│ exstyle_code.npy
│ vtoonify_s026_d0.5.pt
│ vtoonify_s299_d0.5.pt
│ vtoonify_s_d.pt
│ vtoonify_s_d_c.pt
│
├─vtoonify_d_comic
│ exstyle_code.npy
│ vtoonify_s_d.pt
│ vtoonify_s_d_c.pt
│
├─vtoonify_d_pixar
│ exstyle_code.npy
│ vtoonify_s052_d0.5.pt
│ vtoonify_s_d.pt
│ vtoonify_s_d_c.pt
│
├─vtoonify_t_arcane
│ vtoonify.pt
│
├─vtoonify_t_caricature
│ vtoonify.pt
│
├─vtoonify_t_cartoon
│ vtoonify.pt
│
├─vtoonify_t_comic
│ vtoonify.pt
│
└─vtoonify_t_pixar
vtoonify.pt
使用教程
本教程的所使用的资源目录如下:
- 您的视频或图片路径
D:\openai.wiki\VToonify\data - VToonify处理完成后的输出路径
D:\openai.wiki\VToonify\output
环境激活
无论使用哪个模型,都需要先激活环境,并且进入VToonify的项目路径。
激活Conda环境
conda activate D:\openai.wiki\VToonify\vtoonify_env
进入VToonify项目路径
cd /d D:\openai.wiki\VToonify
模型效果
视频转动漫
视频名称为您的视频文件名,自行根据自身视频命名替换即可。
python style_transfer.py --scale_image --content ./data/视频名称.mp4 --video
执行完如上命令行之后稍等片刻,将会在D:\openai.wiki\VToonify\output目录下生成已转换完成的视频文件。
图片转动漫


python style_transfer.py --scale_image


专用模型具有更好的性能
python style_transfer.py --scale_image --content ./data/081680.jpg \
--ckpt ./checkpoint/vtoonify_d_cartoon/vtoonify_s026_d0.5.pt


python style_transfer.py --content ./data/038648.jpg \
--scale_image --padding 600 600 600 600 --style_id 77 \
--ckpt ./checkpoint/vtoonify_d_arcane/vtoonify_s_d.pt

python style_transfer.py --content ./data/038648.jpg \
--scale_image --padding 600 600 600 600 --backbone toonify \
--ckpt ./checkpoint/vtoonify_t_arcane/vtoonify.pt

python style_transfer.py --content ./data/077559.jpg \
--scale_image --padding 600 600 600 600 --style_id 77 \
--ckpt ./checkpoint/vtoonify_d_arcane/vtoonify_s_d.pt

python style_transfer.py --content ./data/077559.jpg \
--scale_image --padding 600 600 600 600 --backbone toonify \
--ckpt ./checkpoint/vtoonify_t_arcane/vtoonify.pt

有一键安装包吗?
@tcq0406 目前还没有
本地部署的话对硬件有什么要求?
@你好老师,请问可以部署在autodl上吗? 显卡最好是1080以上吧,官方没有明确表示哪些硬件条件才可以。
请问站长,你这个配置完可以跑起来了吗?
我显示的报错就是ninja: build stopped subcommand failed.还是解决不了
@zander 我这里是构建成功了的,而且也跑了起来,只不过效果不如官方的效果好。
本地电脑配置不行 部署在autodl上有什么要注意的吗?
@你好老师 我这里没有部署到云平台上尝试过哈,我只是在本地部署的。
方法1:手动打开电脑的环境变量设置,将该路径添加至用户环境变量的phth中即可。
这个环境变量的键名应该 Path 吧
@hyde 是的哈
我部署在autodl上,按步骤安装依赖后,运行,出现以下报错信息是什么原因:
(/root/VToonify/vtoonify_env) root@autodl-container-809011af9e-40b780d5:~/VToonify# python style_transfer.py –scale_image –content ./data/test1.mp4 –video
Load options
backbone: dualstylegan
batch_size: 4
ckpt: ../autodl-tmp/checkpoint/vtoonify_d_cartoon/vtoonify_s_d.pt
color_transfer: False
content: ./data/test1.mp4
cpu: False
exstyle_path: ../autodl-tmp/checkpoint/vtoonify_d_cartoon/exstyle_code.npy
faceparsing_path: ../autodl-tmp/checkpoint/faceparsing.pth
output_path: ./output/
padding: [200, 200, 200, 200]
parsing_map_path: None
scale_image: True
style_degree: 0.5
style_encoder_path: ../autodl-tmp/checkpoint/encoder.pt
style_id: 26
video: True
**************************************************************************************************
Traceback (most recent call last):
File “/root/VToonify/style_transfer.py”, line 79, in
pspencoder = load_psp_standalone(args.style_encoder_path, device)
File “/root/VToonify/util.py”, line 144, in load_psp_standalone
ckpt = torch.load(checkpoint_path, map_location=’cpu’)
File “/root/VToonify/vtoonify_env/lib/python3.9/site-packages/torch/serialization.py”, line 797, in load
with _open_zipfile_reader(opened_file) as opened_zipfile:
File “/root/VToonify/vtoonify_env/lib/python3.9/site-packages/torch/serialization.py”, line 283, in __init__
super().__init__(torch._C.PyTorchFileReader(name_or_buffer))
RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
(/root/VToonify/vtoonify_env) root@autodl-container-809011af9e-40b780d5:~/VToonify#
@你好老师 是不是ckpt = torch.load(checkpoint_path, map_location=torch.device(‘cpu’))这里错了?
@你好老师 您可以尝试使用torch.device(‘cpu’)参数来将模型加载到CPU上,以解决PytorchStreamReader读取zip归档并找不到中央目录的问题。将以下代码行:
ckpt = torch.load(checkpoint_path, map_location='cpu')替换为device = torch.device('cpu')这将确保将模型加载到CPU上,而不是尝试在GPU上加载。ckpt = torch.load(checkpoint_path, map_location=device)
@你好老师 你这好像是PyTorch版本不对,我没有在autodl部署过,没有这方面的经验,建议你把PyTorch卸载,然后安装其它版本试一下。
@你好老师 暂时解决了 ,但是转换视频的时候 选择模型荟报错
@sherry 可以贴一下报错信息吗?
老师您好,请问转换视频 可以选定模型吗?为什么我设定模型就跑不了视频 改成输入图片就可以了 这是问什么呢?
@sherry 您好,这个是可以选定模型的,文章末尾我已经为每个模型给出了相应的代码,按道理来说,只要环境部署的没问题,是可以直接出视频的,代码p
ython style_transfer.py --scale_image --content ./data/视频名称.mp4 --video您好,请问示例中 illustration效果是选哪个模型啊 下载的里面没有看到 谢谢
(C:\Users\pclitchi\Documents\a\VToonify\vtoonify_env) C:\Users\pclitchi\Documents\a\VToonify>python style_transfer.py –scale_image –content ./data/48013.mp4 –video
Traceback (most recent call last):
File “C:\Users\pclitchi\Documents\a\VToonify\style_transfer.py”, line 11, in
from model.vtoonify import VToonify
File “C:\Users\pclitchi\Documents\a\VToonify\model\vtoonify.py”, line 5, in
from model.stylegan.model import ConvLayer, EqualLinear, Generator, ResBlock
File “C:\Users\pclitchi\Documents\a\VToonify\model\stylegan\model.py”, line 11, in
from model.stylegan.op import FusedLeakyReLU, fused_leaky_relu, upfirdn2d, conv2d_gradfix
File “C:\Users\pclitchi\Documents\a\VToonify\model\stylegan\op\__init__.py”, line 1, in
from .fused_act import FusedLeakyReLU, fused_leaky_relu
File “C:\Users\pclitchi\Documents\a\VToonify\model\stylegan\op\fused_act.py”, line 11, in
fused = load(
File “C:\Users\pclitchi\Documents\a\VToonify\vtoonify_env\lib\site-packages\torch\utils\cpp_extension.py”, line 1284, in load
return _jit_compile(
File “C:\Users\pclitchi\Documents\a\VToonify\vtoonify_env\lib\site-packages\torch\utils\cpp_extension.py”, line 1535, in _jit_compile
return _import_module_from_library(name, build_directory, is_python_module)
File “C:\Users\pclitchi\Documents\a\VToonify\vtoonify_env\lib\site-packages\torch\utils\cpp_extension.py”, line 1929, in _import_module_from_library
module = importlib.util.module_from_spec(spec)
ImportError: DLL load failed while importing fused: 找不到指定的模块。
@你好,能看一下这是什么情况吗 模型没找到,重新PIP一下。
@PhiltreX 我也报了这个错,什么模型没找到啊
@你好,能看一下这是什么情况吗 您好,解决了吗,我也是报了这个问题,pip什么包呢?
@akai007 这里有个问题!!!!把环境创建完成后,先安装matplotlib-base=3.3.4!!!要不然会有很多的版本冲突!!!大致根据这个issue安装即可https://github.com/williamyang1991/VToonify/issues/50
这个是不是G卡用不了?
@dssmn G卡是什么卡?
没有独显能操作嘛
有提示在运行中的吗