
Stable Diffusion和Stable Diffusion WebUI是什么关系?
其实stable-diffusion和stable-diffusion-webui就相当于是父子关系,前者是父亲,后者是儿子(WebUI),儿子几乎继承了父亲所有的优点,然后又自我优化,学了很多其它技能,比如您可以为儿子安装一些插件,可以让儿子更听话的为己所用,但父亲是不具备儿子的能力滴。
而且,如果父亲有了新的能力,AUTOMATIC1111大佬会去自动继承父亲的新能力,而且该大佬更新极其高产,每天更新好几次都是常有的,所以完全不用担心这方面的问题。
前提条件
如果您对CMD不太了解,那么在您看如下内容时,可能会感到迷茫和困惑,可以考虑参考本站关于CMD的介绍,以及一些初级教程。
使用Stable Diffusion案例
其实Stable Diffusion本身并没有UI界面,如果想使用就必须调用CMD命令行来执行语句控制程序运行,我想这对于大部分人来说应该是一场噩梦吧,毕竟谁又会去记那么那么多的参数呢?
通过CMD生成绘画
假如我们使用没有图形UI界面的Stable Diffusion来生成一张图片,需要在CMD窗口内输入以下命令:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
其中--prompt后面的即是描述性文字,可以根据需要更改,如果想生成更加细致的内容,那就需要添加非常多的参数。
常用参数
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
总结
一个普通人是记不住这么多参数的,包括大部分程序员也是如此,所以这个时候,有一个大佬站了出来。
使用Stable Diffusion WebUI案例
WebUI介绍
该大佬的Github名为AUTOMATIC1111,在GitHub开源了一个名为stable-diffusion-webui的项目。这个名叫stable-diffusion-webui的项目,最大的便捷之处就是为stable-diffusion制作了图形界面,让我等普通人也可以愉快的使用<code>stable-diffusion</code>,来进行艺术(XP)创作。本站所有关于stable-diffusion的教程都是基本该大佬的WebUI项目。
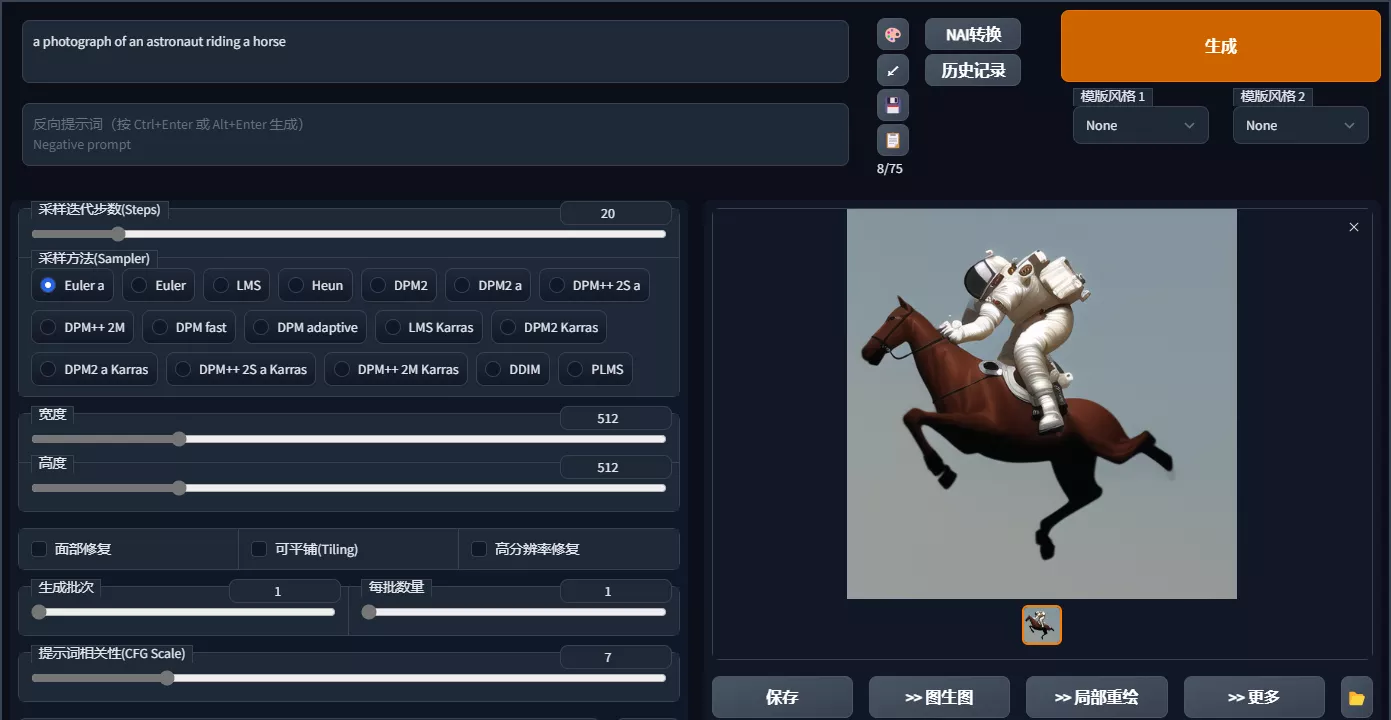
通过WebUI生成绘画
在部署完该项目之后,打开电脑的任意浏览器,输入IP地址127.0.0.1:7860,就可以打开WebUI的界面,然后只输入你想要生成的提示词,稍等片刻就可以看到与你提示词相关的图片就生成好了。



之前一直以为是两个软件
webui的附加功能不能批处理放大图像,提示不识别图片
@gghh 把CMD窗口内的详细信息复制一下