
Depth Library的进阶使用方法
其实本教程是和基础教程一起写出来的,但是关于Depth Library的进阶教程使用方法需要太多前置技能,都放在Depth Library基础教程内给大家讲,可能会让各位基础不太好的同学们看的云里雾里,所以单独拆分出来,大家段式学习,可能效果会更好。
如果您还没看过基础教程,请一定要先看一下,不然本篇内容您可能不太容易理解。
进阶方法介绍
该方法使用openPose算法+Depth Library插件来生成模型,效果比普通方法会更好一些,在普通方法中已经讲过的部分本站在进阶教程中就不废话了。
前置技能
学习此部分内容,需要先了解ControlNet的OpenPose算法,关于此部分的算法使用,本站已经在之前的内容中有所介绍,如果您不理解我下面想讲的内容,请先看下面这篇ControlNet的使用指南。
LoRA
本站教程中所使用的基础模型和角色为LoRA,如果您对LoRA感兴趣,可以阅读下面的文章。
环境设置
除了掌握ControlNet的OpenPose算法之外,我们还需要开启两个特殊选项。
- Stable Diffusion WebUI ->
ControlNet-> Multi ControlNet: Max models amount (requires restart)- 将该参数设置为2
- Stable Diffusion WebUI ->
ControlNet-> Enable CFG-Based guidance- 勾选
然后按顺序点击Apply settings和Reload UI。
做完如上步骤之后,我们将会在ControlNet内看到两个控制窗口(如下图所示),之前只可以添加一张图片去引导图像生成,但是现在可以同时让两张图片相互影响,然后生成最终图片,非常奈斯。
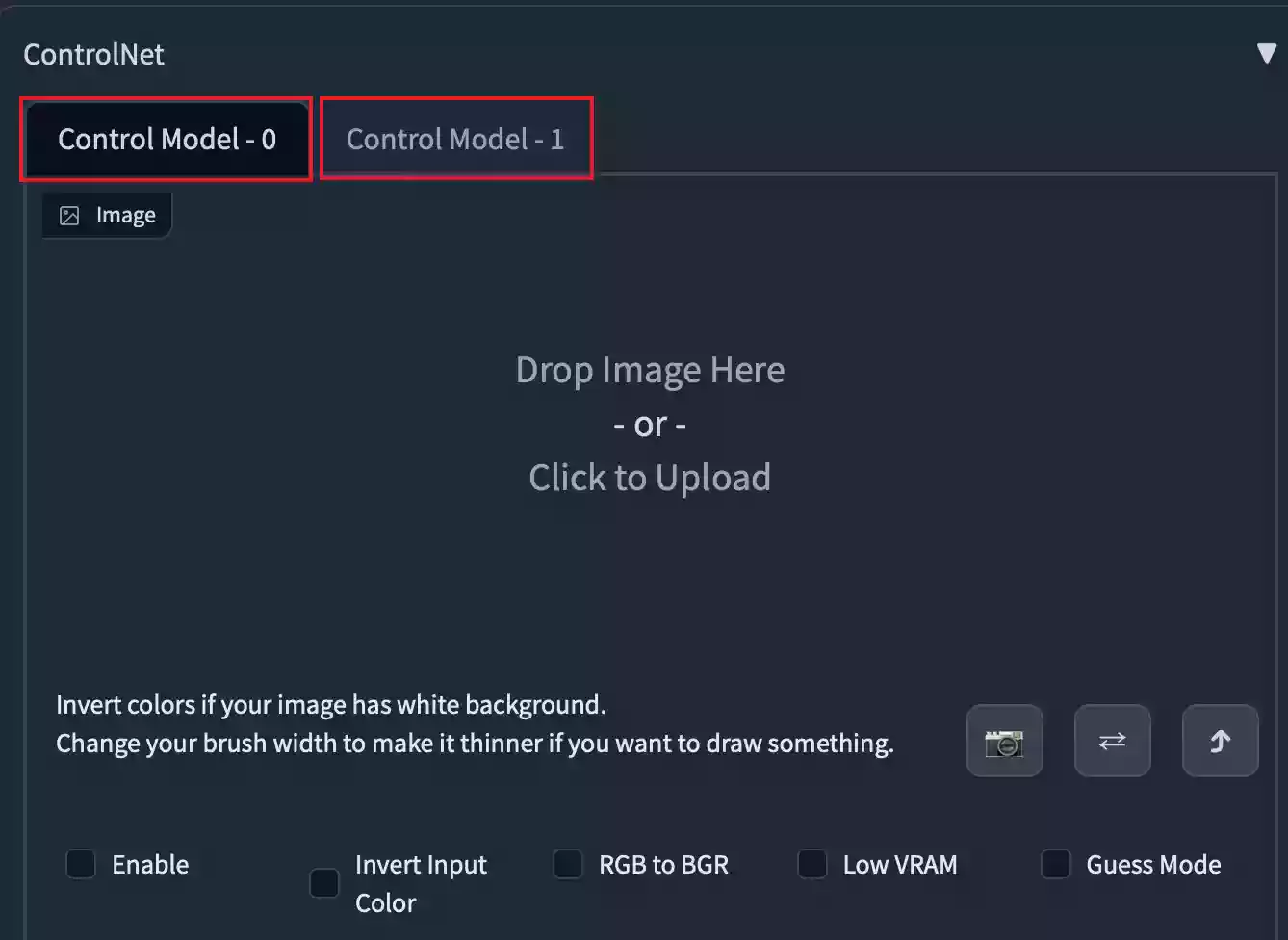
⚠️注意:上所所示中有两个面板,Control Model - 0和Control Model - 1两个面板是相互独立的,互相影响,但数值不通用。
举例1:本站在Control Model - 0设置Weight(权重)数值为0.5,那么Control Model - 1的Weight并不受影响,默认依旧为1。
举例2:本站在Control Model - 0设置Weight(权重)数值为0.7,然后将Control Model - 1的Weight设置为1。那么在通过ControlNet进行引导渲染时,Control Model - 0为主要模型,Control Model - 1为辅助模型,在生成图像时,图像的内容将更加偏向Control Model - 0的画面提示。
姿势提取
既然我们这次使用OpenPose+Depth Library,那我们就需要先提取一套骨骼,模特图仍然是普通用法教程中的基础图片,不做任何修改。


OpenPose骨骼手势摆放
这里在普通方法里面讲过,这里就不做过多阐述了。


Depth Library手势深度图多重控制
OpenPose Editor
下面才是进阶教程的重点,我们先在OpenPose Editor选项卡内,将骨骼图片发送至ControlNet窗口内,此时我们将会在Control Model - 0的窗口内看到发送过来的骨骼图片,如下图所示。
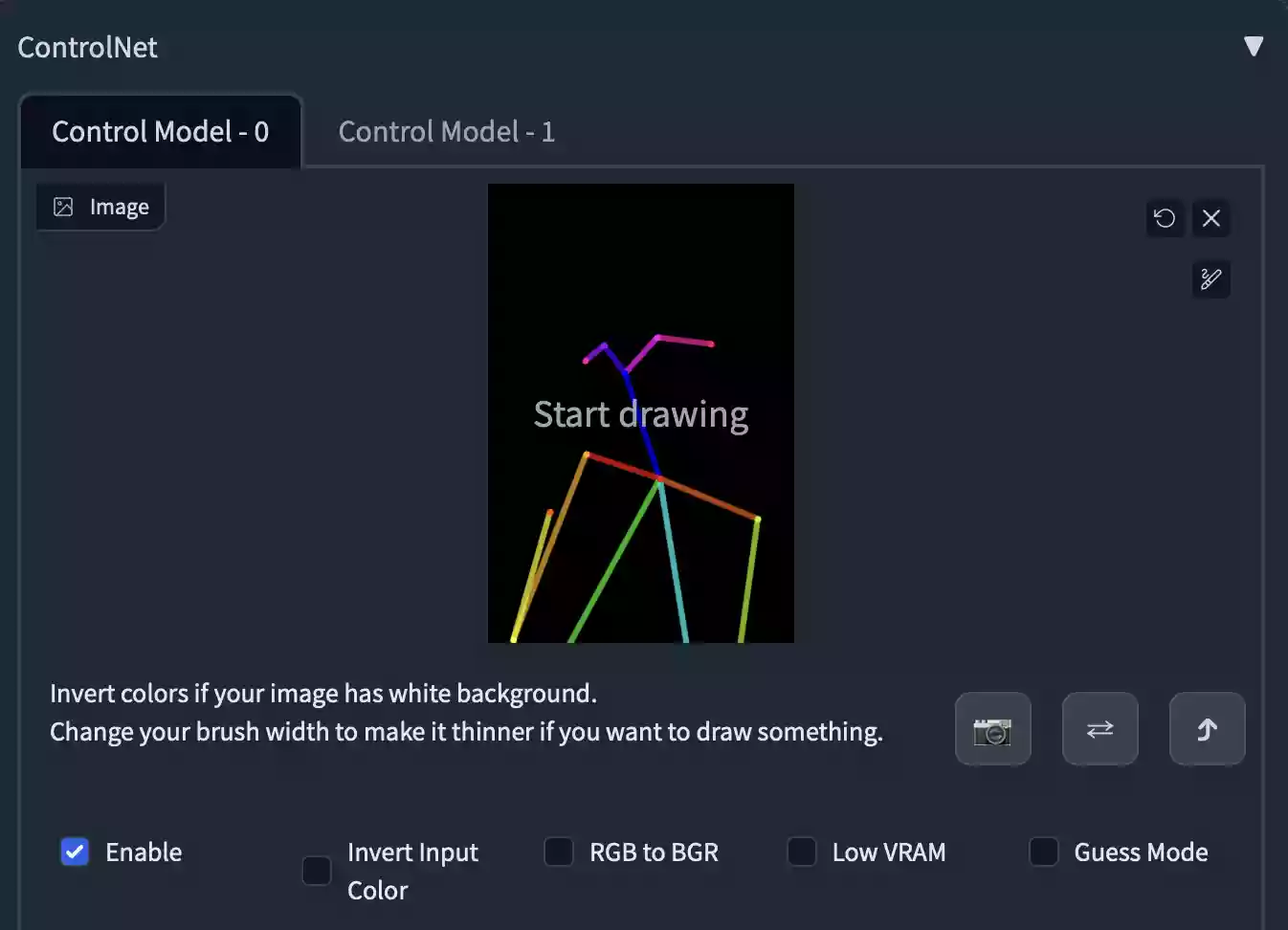
Depth Library
然后再回到Depth Library选项卡,此时我们不要点击Send to ControlNet按钮,不然只会覆盖Control Model - 0的窗口内的图片,而不是自动加载到Control Model - 1的窗口中。
我们应该点击Save PNG按钮,先将这张已经摆放好的手势图片保存至本地,然后使用格式转换软件,将该PNG图片转换为JPG格式,然后在ControlNet内的Control Model - 1窗口加载已经转换为JPG格式的手势深度图,如果不转换为JPG格式无法上传。
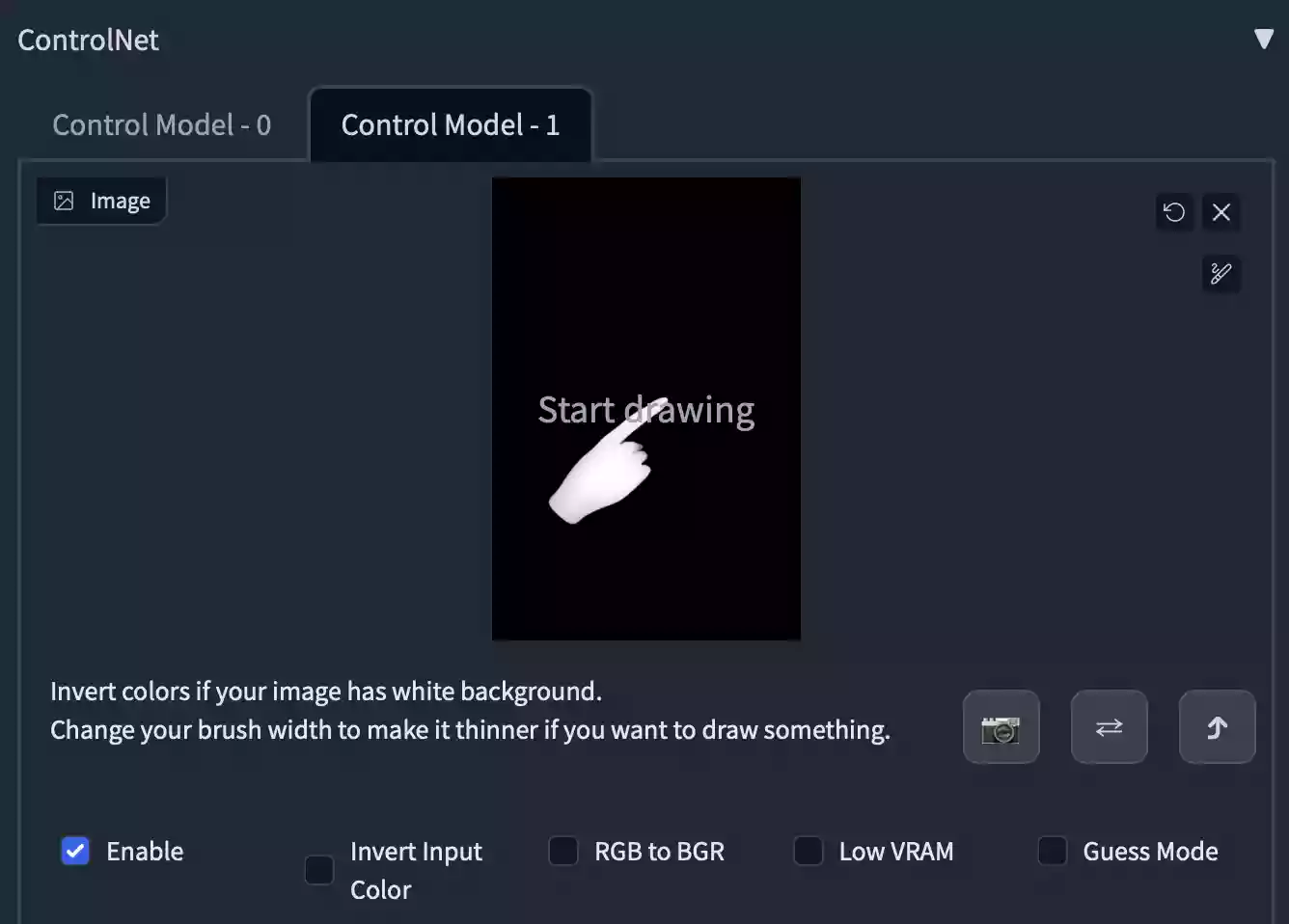
重新引导
此时,我们已经完成了所有必要步骤,我们来进行最后的设置。
Control Model - 0,将该选项卡内的Enable勾选,然后设置Preprocessor为None,设置Model为control_sd15_openpose,其它参数保持默认即可。
Control Model - 1,将该选项卡内的Enable勾选,然后设置Preprocessor为None,设置Model为control_sd15_depth,其它参数保持默认即可。
然后直接点击平时生成图片的那个生成按钮,生成一张图片来看看效果。


可以看到,手指的效果通过使用ControlNet的多重控制,现在的效果已经非常奈斯啦!
自定义手势
目前该扩展插件中的手势库图片还比较少,手势的深度也是无法控制的,估计以后会给手势加一个透明通道调节的功能,这样可以控制手势渲染强度。
其实我们也可以自行上传手势深度图,图片可以从三维软中自己渲染,或者实拍之后自行提取也可以。
然后把已经处理好的深度图存放在到*/stable-diffusion-webui/extensions/sd_webui-depth-lib/maps文件夹中,刷新一下UI界面,就可以看到新加的自定义手势库啦。
总结
其实这个效果还算是看的过去,但是调节需要一些经验,因为只是通过ControlNet进行引导就已经比较复杂了,更何款现在的多重控制功能。
好啦,最近比较懒,不太想工作,进阶教程先写这么多。如果有更好的相关解决方案,本站将会为您带来高阶用法教程,掰掰。


有个oline 3D openpose editor,相比之下是不是把以上很多东西都省略了?