
ComfyUI|AI绘画新姿势
ComfyUI是一种基于图形/节点/流程图的界面设计工具,可用于创建稳定扩散AI艺术生成的图像管道。该工具具有模块化和可定制的稳定扩散方法,已经在AI艺术社区中引起了轰动。它支持Stable Diffusion1.x和Stable Diffusion2.x,具有异步队列系统和部分重新执行功能,并允许用户在低VRAM的GPU上运行。
此外,ComfyUI还支持各种功能和模型,包括像ESRGAN、ESRGAN变体、SwinIR和Swin2SR这样的升级模型,可以更加轻松地创造出惊人的图像和作品。该工具还可以加载包含种子的完整工作流程,便于与其他艺术家共享和协作。ComfyUI是一个功能强大的界面,为稳定扩散AI艺术生成提供了极大的便利和灵活性。
软件下载
官网下载:
https://github.com/comfyanonymous/ComfyUI
网盘下载
电脑内已安装过Stable Diffusion,请下载此安装包:
电脑内未安装过Stable Diffusion,或您希望使用CUP来运行ComfyUI,请下载此安装包:
安装教程
关于ComfyUI的安装,其实是非常方便的,如果您的电脑之前已经安装联想过Stable Diffusion或Stable Diffusion WebUI,那您其实已经将所有相关依赖环境部署完毕。此时您使用ComfyUI时,只需要先激活Stable Diffusion的依赖环境,然后就可以启动并使用ComfyUI啦,无需单独再次部署ComfyUI。
已安装SD
如果您的电脑内存在已经安装部署成功的Stable Diffusion,那么您仅需要执行以下几行命令即可使用ComfyUI,非常便捷。
在开始之前,我们需要您提前下载好所需要的文件,也就是ComfyUI-master文件,然后将其解压至与Stable Diffusion WebUI的同级目录,目录结构如下:
D:\openai.wiki └─ComfyUI └─stable-diffusion-webui └─...
目前所有准备工作已经结束,下面开始使用教学。
1.我们先激活电脑内已经存在的Stable Diffusion虚拟环境,这个虚拟环境的激活文件一般在.\stable-diffusion-webui\venv\bin\activate.bat。
本站完整路径为D:\openai.wiki\stable-diffusion-webui\venv\Scripts\activate.bat,请您根据自身情况找到您自己的bat文件相对位置。
打开CMD窗口,执行如下命令激活Stable Diffusion的依赖环境:
D:\openai.wiki\stable-diffusion-webui\venv\Scripts\activate.bat
执行如下命令,跳转至ComfyUI目录。
cd /d D:\openai.wiki\ComfyUI
执行如下命令,运行ComfyUI的主脚本。
python main.py
执行上面的命令之后,需要等待一分钟左右,因为本站除系统盘之外都是非固态硬盘,所以加载速度比较慢。一分钟左右之后,您将会看到如下界面:
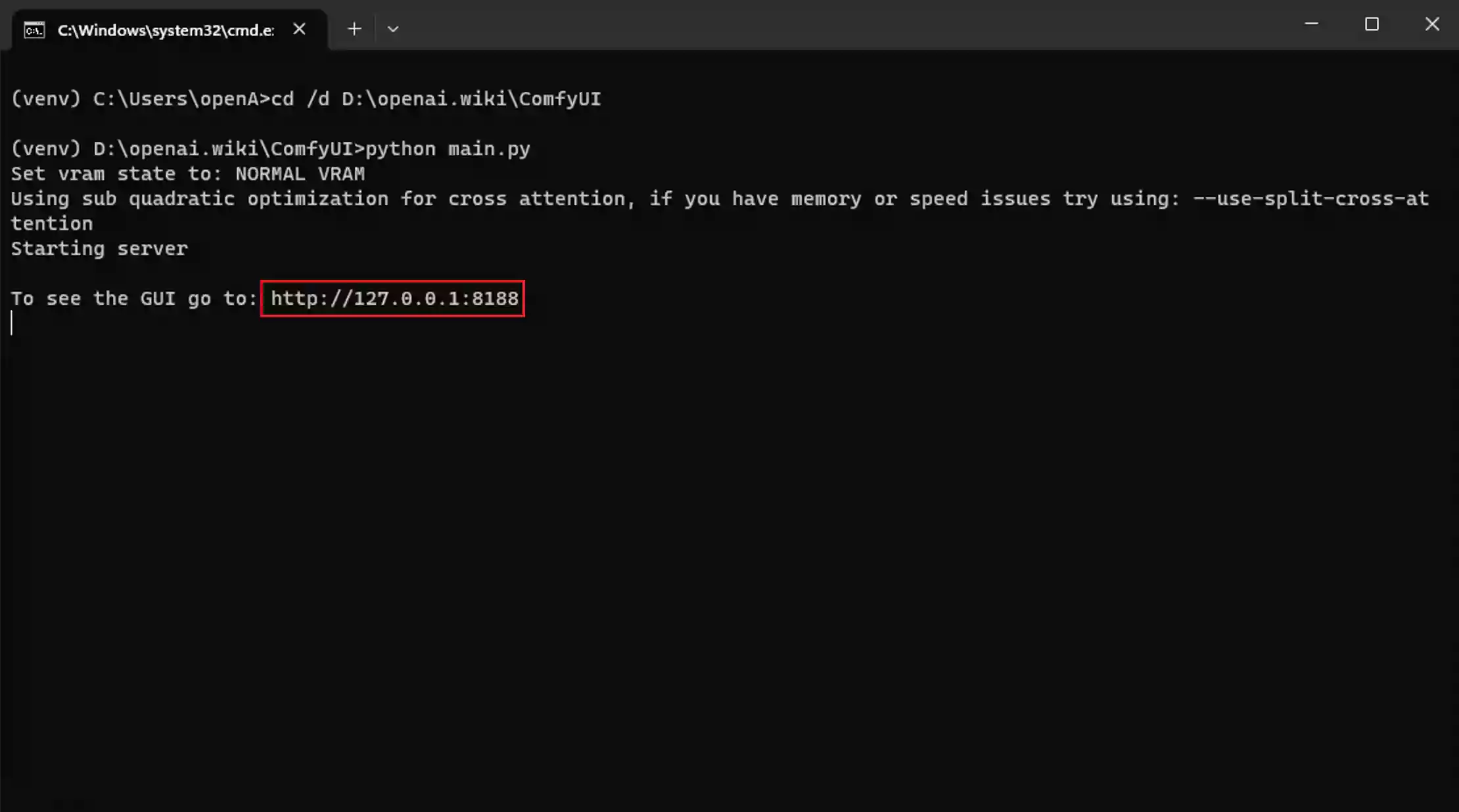
这代表相应的依赖环境已经加载完毕,我们此时可以通过浏览器打开CMD窗口内给出的网址http://127.0.0.1:8188,打开之后将会看到如下界面:
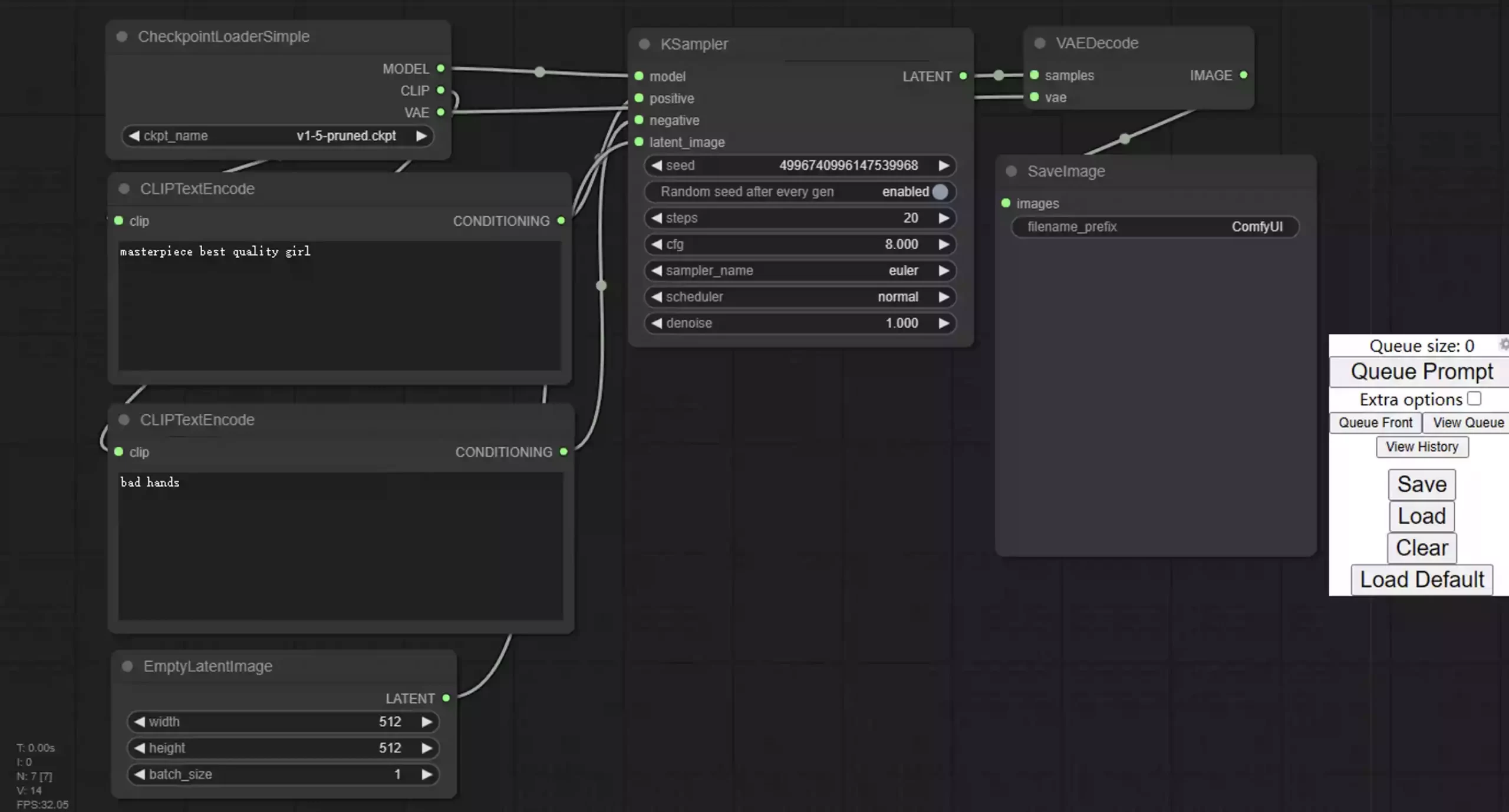
至此,在已安装过Stable Diffusion的电脑内部署ComfyUI已经安装完毕,但是目前模型还未被正确放置,所以运行之后是会报错的,关于模型放置目录的相关问题,请直接看本文末尾处。
未安装过Stable Diffusion
如果您未安装过Stable Diffusion,那么您的电脑系统环境一定是干干净净的,所以需要下载ComfyUI的完整安装包。在上面本站已经提供了名为ComfyUI_windows_portable_nvidia_cu118_or_cpu的压缩包,本站将其解压至D盘的openai.wiki文件夹内。
完整目录为:D:\openai.wiki\ComfyUI_windows_portable,目录结构如下
D:\openai.wiki └─ComfyUI_windows_portable └─...
在ComfyUI_windows_portable目录下,我们可以看到如下文件,本站已对主要文件进行备注:
D:\openai.wiki\ComfyUI_windows_portable
└─ComfyUI
└─models //模型存放路径
└─python_embeded
└─update
└─update.py
└─update_comfyui.bat //更新ComfyUI
└─update_comfyui_and_python_dependencies.bat //更新comfyui和python依赖项
└─README_VERY_IMPORTANT.txt //说明文件
└─run_cpu.bat //以CPU方式运行SD,建议显卡不佳的用户使用。
└─run_nvidia_gpu.bat //以英伟达GPU方式运行SD
我们先运行D:\openai.wiki\ComfyUI_windows_portable\update\update_comfyui_and_python_dependencies.bat批处理文件,执行该文件之后等待片刻将会自动更新ComfyUI和Python依赖项。
在更新相关依赖环境之后,我们执行D:\openai.wiki\ComfyUI_windows_portable\run_nvidia_gpu.bat批处理文件夹,将会自动加载ComfyUI的环境,大概需要等待几分钟,然后将会看到如下界面:
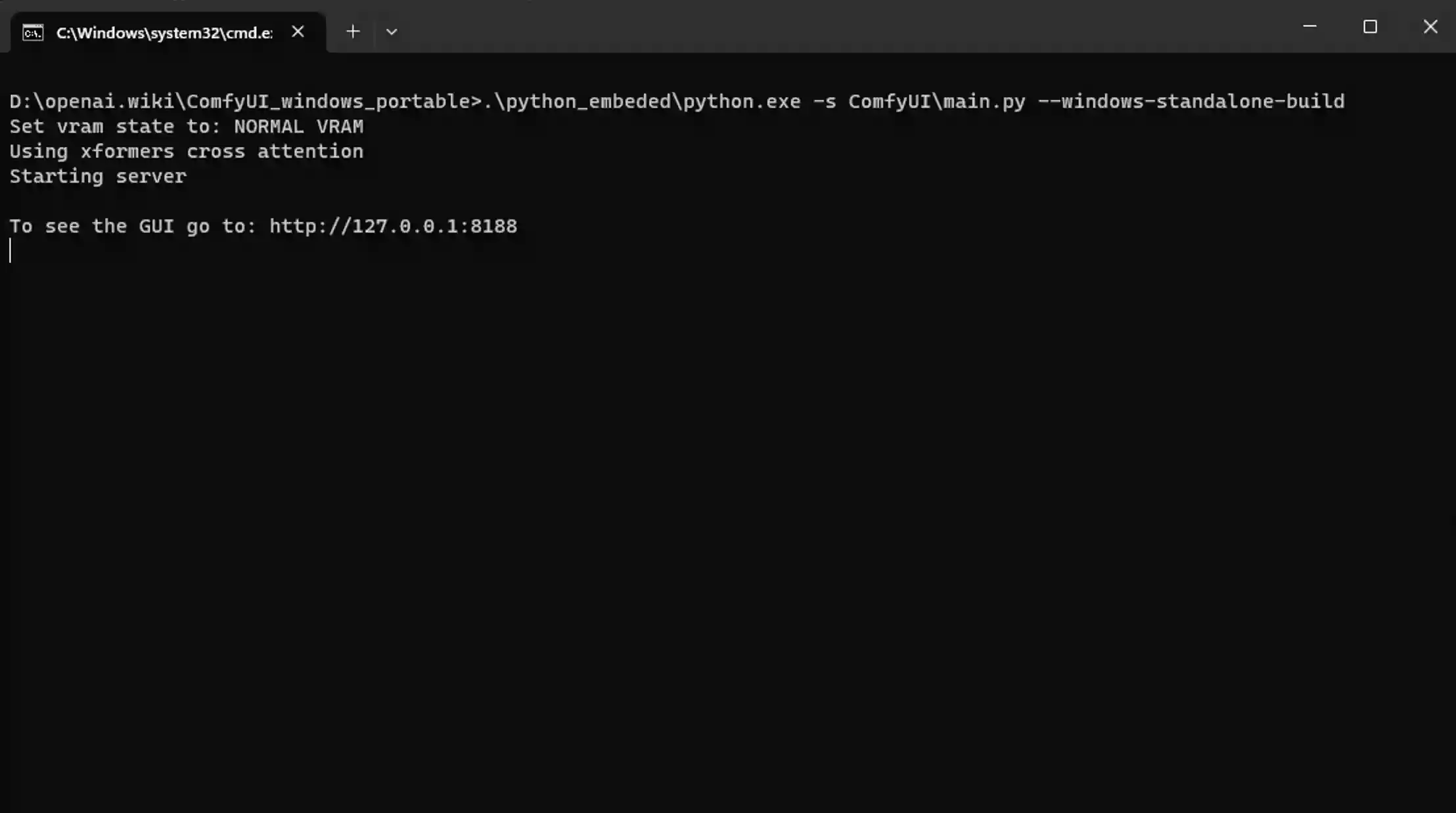
我们根据提示内容,打开网页http://127.0.0.1:8188,将会看到如下界面:
但是此时还无法使用,在使用之前,我们需要先安装模型,关于模型的安装请参考以下内容。
模型安装
虽然ComfyUI可以共用Stable Diffusion的依赖环境,但模型并不会自动共享路径。
ComfyUI的模型目录结构如下,需要您将相关模型按照如下目录存放。
| 目录 | 描述 |
|---|---|
| ComfyUI/models/checkpoints | 基础模型:如SD1.5、NovelAI、chilloutmix等大型模型。 |
| ComfyUI/models/embeddings | 一般为.pt后缀的风格模型 |
| ComfyUI/models/loras | LoRA角色模型 |
| ComfyUI/models/vae | 滤镜文件 |
| ComfyUI/models/controlnet | Controlnet的相关模型 |
注意:新增模型后,需要重启ComfyUI服务。
举例1:
本站有一个Stable Diffusion的官网基础模型,版本为v1.5,名称为v1-5-pruned.ckpt,本站的ComfyUI项目路径为D:\openai.wiki\ComfyUI,那么需要将这个名为v1-5-pruned.ckpt模型复制或移动到D:\openai.wiki\ComfyUI\models\checkpoints路径下。
D:\openai.wiki\ComfyUI\models> ├─checkpoints │ put_checkpoints_here │ v1-5-pruned.ckpt //新增模型 ├─clip ├─clip_vision ├─configs ├─controlnet ├─embeddings ├─loras ├─style_models ├─upscale_models └─vae
举例2:
本站有一个Stable Diffusion的LoRA角色模型,名称为iu_V20.safetensors,本站的ComfyUI项目路径为D:\openai.wiki\ComfyUI,那么需要将这个名为iu_V20.safetensors模型复制或移动到D:\openai.wiki\ComfyUI\models\loras路径下。
D:\openai.wiki\ComfyUI\models> ├─checkpoints │ put_checkpoints_here │ v1-5-pruned.ckpt ├─clip ├─clip_vision ├─configs ├─controlnet ├─embeddings ├─loras │ iu_V20.safetensors //新增模型 ├─style_models ├─upscale_models └─vae
举例3:
如果您使用的是ComfyUI_windows_portable_nvidia_cu118_or_cpu压缩包,那么模型应该放在如下位置:
D:\openai.wiki\ComfyUI_windows_portable
└─ComfyUI
└─models //模型存放路径
└─python_embeded
└─update
└─README_VERY_IMPORTANT.txt
└─run_cpu.bat
└─run_nvidia_gpu.bat
使用教程
在您配置好ComfyUI并且模型正确放置之后,打开网页http://127.0.0.1:8188,选择模型之后点击右侧的Queue Prompt按钮,稍等片刻即可正确生成图像啦。
注意:第一次点击生成按钮后,需要加载模型,时间会比较久,大概在几分钟左右,所以不要多次点击,耐心等待即可。
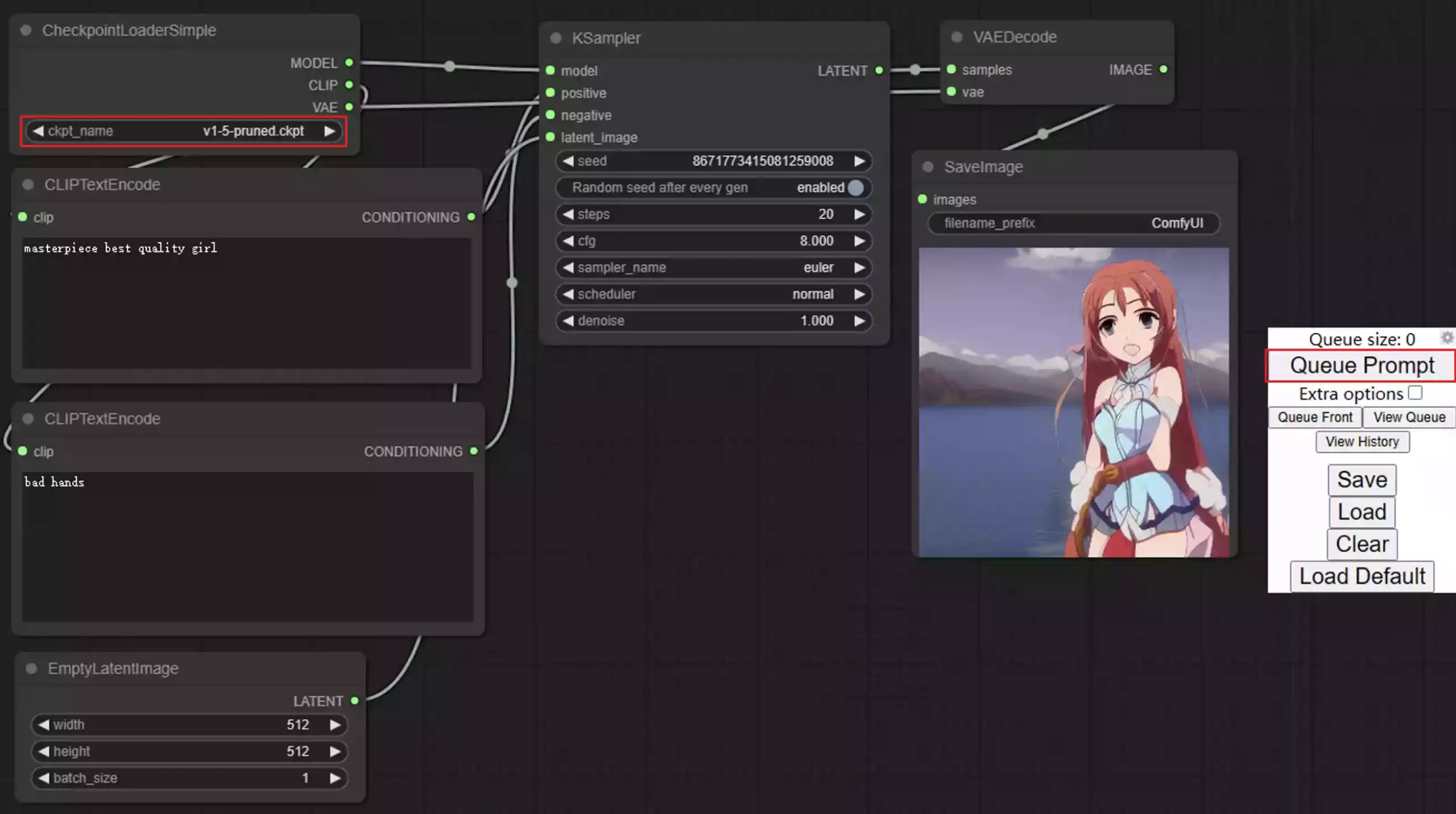
关于详细的使用教程,本站后续将会单独写一篇相关内容,请稍等一段时间。



没什么问题,只是想向站长表示感谢。中文媒体里能找到的信息,站长这里最详细,教程最用心,特次留言感谢。
@Grasinko 您客气哈,我也踩坑了很久。
感谢站长。
用 ChatGPT 给这个 UI 写了个启动脚本。目录结构按照上面流程的话,下面的内容保存成 .bat 以后放到 ComfyUI 的文件夹内就行了,自己也可以根据实际目录结构修改:
@echo off
REM Step 1: Go to the parent directory
cd ..
REM Step 2: Activate the virtual environment
call stable-diffusion-webui\venv\Scripts\activate.bat
REM Step 3: Go back to the current directory
cd /d “%~dp0”
REM Step 4: Run the main.py script using Python
python main.py
echo Done!
另外,也可以通过 mklink 给 ComfyUI 和 Stable diffusion 的模型做文件夹的跳转,这样不仅节省空间,更新起来也方便,不用再复制一次,以 LoRA 为例:
1. 删掉 ComfyUI 下面原来的 LoRA 文件夹( /models/loras)
2. 打开命令行,根据自己的路径调整下面的命令:
mklink /d “C:\AI\ComfyUI\models\loras” “C:\AI\stable-diffusion-webui\models\lora”
这个也是我跟着 ChatGPT 学的,世界真的在变化。
@Erelief 感谢您的补充,我当时的确考虑到了mklink,但是最近一堆麻烦事,所以也就没测试可行性。
@Erelief 请问下是如何描述给ChatGPT的? 本身这个脚本并不复杂,但是按照我的理解提问应该比结果更复杂。
我自己写的脚本就一行:
..\stable-diffusion-webui\automatic\python.exe main.py
@fengmu 基本就是根据脚本里的注释问的:请写一个批处理文件(bat)去执行下面的步骤:1.回到上层文件夹 2.执行 \stable-diffusion-webui\venv\Scripts\activate.bat 3. 回到这个bat所在的文件夹 4.执行 python main.py
我是大体知道 bat 能做这个事,但是 bat 一点也不会写的情况下这么做的。用的就是免费的 3.5。
@fengmu 基本就是根据脚本里的注释问的:请写一个批处理文件(bat)去执行下面的步骤:1.回到上层文件夹 2.执行 \stable-diffusion-webui\venv\Scripts\activate.bat 3. 回到这个bat所在的文件夹 4.执行 python main.py
和本地的webui比有什么优缺点
@lmb 我个人觉得不方便,用起来太麻烦了。
请问 这个是需要同时启动stable diffusion后 再启动comfy UI吗?
@Alan 不用的,只需要启动ComfyUI就行啦,启动SD是指启动它的环境依赖。
用comfyui做了一个项目,它最大的功能在于生成的图片会自动保存一个工作流,然后想要找到某张图片是哪个参数哪个模型,直接在UI里面加载这个图片就可以,(可以理解为自动保存工程文件)但是缺点是,发布的比较晚,在插件的支持上并不如webUI来的多,而且安装插件也没有webUI来的快捷。说实话,我的建议还是再等等,等某个公司可以把这些东西整合成一个完整的整合包就完事了。
ComfyUI|Stable Diffusion GUI 与 本地化部署Stable Diffusion WebUI 有何区别?
求大佬!
@openai.wiki的忠实粉丝 其实没有什么区别,可以理解为只是界面不一样呢。
venv “D:\openai.wiki\stable-diffusion-webui\venv\Scripts\Python.exe”
==============================================================================================================
INCOMPATIBLE PYTHON VERSION
This program is tested with 3.10.6 Python, but you have 3.9.12.
If you encounter an error with “RuntimeError: Couldn’t install torch.” message,
or any other error regarding unsuccessful package (library) installation,
please downgrade (or upgrade) to the latest version of 3.10 Python
and delete current Python and “venv” folder in WebUI’s directory.
You can download 3.10 Python from here: https://www.python.org/downloads/release/python-3109/
Alternatively, use a binary release of WebUI: https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases
Use –skip-python-version-check to suppress this warning.
==============================================================================================================
Python 3.9.12 (main, Apr 4 2022, 05:22:27) [MSC v.1916 64 bit (AMD64)]
Commit hash: 22bcc7be428c94e9408f589966c2040187245d81
Installing requirements for Web UI
Launching Web UI with arguments:
No module ‘xformers’. Proceeding without it.
Loading weights [a7529df023] from D:\openai.wiki\stable-diffusion-webui\models\Stable-diffusion\final-pruned.ckpt
Creating model from config: D:\openai.wiki\stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Loading VAE weights found near the checkpoint: D:\openai.wiki\stable-diffusion-webui\models\Stable-diffusion\final-pruned.vae.pt
loading stable diffusion model: OutOfMemoryError
Traceback (most recent call last):
File “D:\openai.wiki\stable-diffusion-webui\webui.py”, line 139, in initialize
modules.sd_models.load_model()
File “D:\openai.wiki\stable-diffusion-webui\modules\sd_models.py”, line 449, in load_model
sd_model.to(shared.device)
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\lightning_fabric\utilities\device_dtype_mixin.py”, line 54, in to
return super().to(*args, **kwargs)
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 989, in to
return self._apply(convert)
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 641, in _apply
module._apply(fn)
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 641, in _apply
module._apply(fn)
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 641, in _apply
module._apply(fn)
[Previous line repeated 2 more times]
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 664, in _apply
param_applied = fn(param)
File “D:\openai.wiki\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 987, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 2.00 GiB total capacity; 1.66 GiB already allocated; 0 bytes free; 1.70 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Stable diffusion model failed to load, exiting
求大佬!!
@openai.wiki的忠实粉丝 还是显存不足哈,您发一下显卡型号,我这里帮您看一下。
@openai.wiki的忠实粉丝 同样,还是显存不足,报CUDA错误。
@PhiltreX NVIDIA GeForce MX150
这个
谢谢哈
@openai.wiki的忠实粉丝 GeForce MX150的显存一般为2G或4G,如果您的是2G显存就可以放弃啦,如果是4G显存或者还可以挣扎一下,打开SD目录下的
webui-user.bat文件,将其中的set COMMANDLINE_ARGS=修改为set COMMANDLINE_ARGS=--lowvram,如果还是不行的话,那就没办法咯。iMac能安装使用么?