
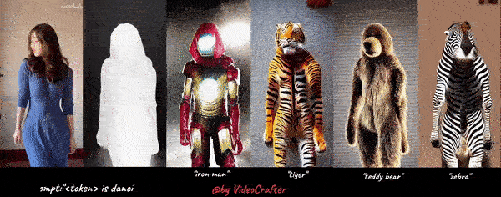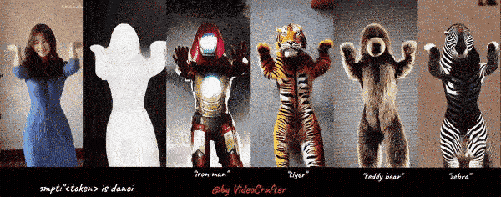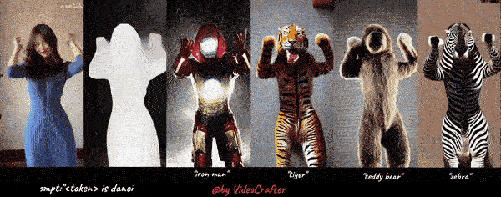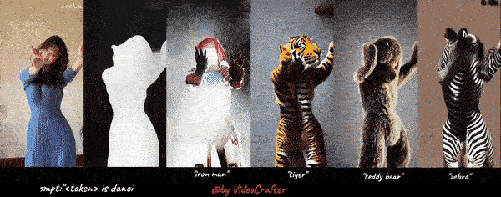
免费开源文本生成视频&风格转换VideoCrafter工具
VideoCrafter是一个开源视频生成和编辑工具箱,用于制作视频内容。支持从文本Prompt提示词生成视频,支持LoRA模型,另外对已有视频进行风格转换也是支持的,类似于SD绘画的图生图功能。
整体生成速度很快,但效果并不是很理解,而且高级效果调试方式需要配合命令行,对于新手可能不太友好。
项目介绍
它目前包括以下三种类型的模型:

项目功能
1.基本 T2V:通用文本到视频生成
我们提供了一个基于潜在视频扩散模型(LVDM)的基本文本到视频(T2V)生成模型。 它可以根据输入的文本描述合成逼真的视频。




2.视频LoRA: 使用 LoRA 生成个性化的文本到视频
基于预训练的LVDM,我们可以通过在一组描述特定概念的视频剪辑或图像上进行微调来创建自己的视频生成模型。
我们采用 LoRA 来实现微调,因为它易于训练并且需要更少的计算资源.
以下是我们的四个 VideoLoRA 模型的生成结果,这些模型在四种不同风格的视频剪辑上进行了训练。
通过提供描述视频内容的句子以及 LoRA 触发词 (在 LoRA 训练期间指定), 它可以生成具有所需样式的视频 (或主题/概念).
输入到四个 VideoLoRA 模型的结果:A monkey is playing a piano, ${trigger_word}




每个 VideoLoRA 的触发词在生成结果下方注释。
3. 视频控制:具有更多条件控制的视频生成
为了增强T2V模型的可控能力,我们开发了受T2I适配器启发的条件适配器。 通过将轻量级适配器模块插入 T2V 模型,我们可以获得具有更详细控制信号(例如深度)的生成结果。
输入文本:Ironman is fighting against the enemy, big fire in the background, photorealistic, 4k





更新计划
- ✅拥抱脸Gradio演示和Colab
- ✅释放视频控制模型以获得深度
- ✅发布无水印的新基本模型
- ❎释放其他类型(如精明和姿势)的视频控制模型
- ❎技术报告
- ❎发布 VideoLoRA 的训练代码
- ❎发布 512×512 高分辨率版本的视频控制模型
- ❎更多定制型号
项目仓库
GitHub:VideoCrafter/VideoCrafter:用于文本到视频生成和编辑的工具包 (github.com)
前置条件
在执行项目安装之前,我们还需要安装Git和Conda,如果您的电脑还未安装这两款软件,请先根据本站所给出的教程安装。
Windows系统安装Git请参阅此文章:
Windows系统安装Conda请参阅此文章:
网络问题
在安装过程中,你可能即便开启了魔法上网也无法下载一些编程依赖库,关于魔法上网的相关配置问题不方便在站内讲解,请自行查看【魔法上网】的教程内容。
安装教程
如果您是初学者,对于命令行不太理解,那么请按下键盘上的Win键+R键后,在弹出的新窗口内输入CMD并按下回车键,在CMD窗口中按顺序执行如下的每一条命令。
首先我们需要确认一个工作目录,用来存放该项目的相关环境依赖文件。本站所选择的目录为D盘的根目录下openai.wiki文件夹,完整路径为:D:\openai.wiki。
在CMD中执行如下命令,这将会自动检测D盘是否在openai.wiki文件夹,没有则自动创建该文件夹。
if not exist D:\openai.wiki mkdir D:\openai.wiki
继续执行如下命令,在CMD中强制切换当前工作路径为D盘的openai.wiki文件夹。
cd /d D:\openai.wiki
拉取该项目的Github仓库文件,将其下载至openai.wiki文件夹内。
git clone https://github.com/VideoCrafter/VideoCrafter.git
环境部署
在CMD中执行如下命令,强制切换至VideoCrafter的项目目录。
cd /d D:\openai.wiki\VideoCrafter
在CMD中执行下面的命令行,创建Conda虚拟环境至该项目的目录中,方便日后重装系统也能够正常使用,无需重新部署环境。
conda create -y -p D:\openai.wiki\VideoCrafter\ENV python=3.8.5
初始化Conda环境,防止后续操作可能存在报错等问题。
conda init cmd.exe
激活已创建的Conda环境,这样可以将我们后续所需要的所有环境依赖都安装至此环境下。
conda activate D:\openai.wiki\VideoCrafter\ENV
执行如下命令,安装该项目的相关模块依赖库。
pip install -r requirements.txt
如果你需要WebUI界面,而非只是通过命令行去操作,那么推荐安装下面的界面依赖库。
pip install gradio
模型下载
官方下载和网盘下载方式,二选其一即可。如果你的网络环境不允许,那么还是推荐使用国内网盘的。
官方下载
Hugging Face:VideoCrafter/t2v-version-1-1 at main (huggingface.co)
网盘下载
关于此项目的模型,本站已为您下载并整理好。如果你不方便通过官网下载,可以使用本站所提供的网盘下载地址。
模型安装
在您下载完成模型之后,将名为models的文件夹,移动至该项目的根目录下即可。
运行方式
在以后每次运行该项目时,只需要先激活我们刚刚所创建的Conda虚拟Python环境,然后运行启动文件即可。
在CMD中执行如下命令,强制切换至项目目录文件夹。
cd /d D:\openai.wiki\VideoCrafter
激活已创建的Conda环境,这样才可以正常使用该项目,否则将会自动调用系统中的默认Python。
conda activate D:\openai.wiki\VideoCrafter\ENV
在CMD中执行如下代码,即可自动生成视频,生成后的视频文件位于项目根目录下的results文件夹内。
python scripts/sample_text2video.py ^
--ckpt_path "models/base_t2v/model.ckpt" ^
--config_path "models/base_t2v/model_config.yaml" ^
--prompt "astronaut riding a horse" ^
--save_dir "results/" ^
--n_samples 1 ^
--batch_size 1 ^
--seed 1000 ^
--show_denoising_progress
推理示例
WebUI
该方式较为简洁,但是可自定义性比较低,只可以简单使用。在CMD中执行如下代码,等待片刻之后即可看到CMD窗口内已经存在一串网址。
python gradio_app.py
已下是运行完成后,自动加载出的命令行反馈。
(D:\openai.wiki\VideoCrafter\ENV) D:\openai.wiki\VideoCrafter>python gradio_app.py Loading model from models/base_t2v/model.ckpt LatentDiffusion: Running in eps-prediction mode Successfully initialize the diffusion model ! DiffusionWrapper has 958.92 M params. making attention of type 'vanilla' with 512 in_channels Working with z of shape (1, 4, 32, 32) = 4096 dimensions. making attention of type 'vanilla' with 512 in_channels gradio_app.py:87: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead. with gr.Row().style(equal_height=False): Running on local URL: http://127.0.0.1:7860
在浏览器中打开http://127.0.0.1:7860即可打开该项目的WebUI界面,界面如下。
可以点击下面的Examples区域,快速应用一些内置的预设,然后点击Send按钮即可开始生成。
文字转视频
在CMD中执行如下代码,即可生成视频,我们也可以根据自身情况做出相应更改,一般来说只需要更改提示词即可。
python scripts/sample_text2video.py ^
--ckpt_path "models/base_t2v/model.ckpt" ^
--config_path "models/base_t2v/model_config.yaml" ^
--prompt "astronaut riding a horse" ^
--save_dir "results/" ^
--n_samples 1 ^
--batch_size 1 ^
--seed 1000 ^
--show_denoising_progress
以下是所有参数的解析,可根据自身情况调整:
- –ckpt_path:模型路径
- –config_path:模型配置路径(yaml 文件)
- –n_samples:每个文本提示有多少个样本,默认为2。
- –prompt:输入文本提示为text2video(一句话或一个txt文件)。
- –batch_size:用于采样的视频批量大小
- –save_dir:生成后的视频保存路径
- –gpu_id:指定你想要使用的 GPU 索引
- –seed:种子数值,相同的设置和种子将会生成相同的视频。
- –num_frames:指定输出视频的帧数,例如 64 帧。
- –ddp:如果你有多个 GPU,最好启用它
视频LoRA
python scripts/sample_text2video.py ^
--ckpt_path "models/base_t2v/model.ckpt" ^
--config_path "models/base_t2v/model_config.yaml" ^
--prompt "astronaut riding a horse" ^
--save_dir "results/" ^
--n_samples 1 ^
--batch_size 1 ^
--seed 1000 ^
--show_denoising_progress ^
--lora_path "models/videolora/lora_001_Loving_Vincent_style.ckpt" ^
--lora_trigger_word ", Loving Vincent style" ^
--lora_scale 1.0
以下是之前未讲到的一些新增参数功能解释,已讲部分不做赘述:
- –show_denoising_progress:采样时是否显示去噪进度,默认为否。
- –lora_path:LoRA模型路径+模型名称
- –lora_trigger_word:LoRA的风格
- –lora_scale:LoRA权重
目前已有可用的官方LoRA模型如下:
D:\openai.wiki\VideoCrafter\models\videolora └─lora_001_Loving_Vincent_style.ckpt └─lora_002_frozenmovie_style.ckpt └─lora_003_MakotoShinkaiYourName_style.ckpt └─lora_004_coco_style.ckpt └─lora_004_coco_style_v2.ckpt
如果你要使用其它LoRA模型,那么请更改生成时的命令为如下内容:
LORA_PATH="models/videolora/lora_001_Loving_Vincent_style.ckpt" TAG=", Loving Vincent style" LORA_PATH="models/videolora/lora_002_frozenmovie_style.ckpt" TAG=", frozenmovie style" LORA_PATH="models/videolora/lora_003_MakotoShinkaiYourName_style.ckpt" TAG=", MakotoShinkaiYourName style" LORA_PATH="models/videolora/lora_004_coco_style.ckpt" TAG=", coco style"
如果你觉得LoRA的权重占比过少,那么可以通过调整lora_scale参数的数值来调整,以下是各参数的LoRA权重占比情况的官方示例。






视频控制
该功能并不是直接通过文字生成视频,而是使用已有视频生成一个相关视频,你可以理解为SD的图生图功能。
python scripts/sample_text2video_adapter.py ^
--ckpt_path "models/base_t2v/model.ckpt" ^
--base "models/adapter_t2v_depth/model_config.yaml" ^
--prompt "An ostrich walking in the desert, photorealistic, 4k" ^
--savedir "results/video_adapter" ^
--seed 123 ^
--adapter_ckpt "models/adapter_t2v_depth/adapter.pth" ^
--bs 1 --height 256 --width 256 ^
--frame_stride -1 ^
--unconditional_guidance_scale 15.0 ^
--ddim_steps 50 ^
--ddim_eta 1.0 ^
--video "input/flamingo.mp4"
以下是之前未讲到的一些新增参数功能解释,已讲部分不做赘述:
- –adapter_ckpt:adapter模型路径
- –bs:用于推理的批量大小
- –height:图像高度,以像素空间为单位
- –width:图像宽度,以像素空间为单位
- –frame_stride:从输入视频中提取帧
- –unconditional_guidance_scale:prompt classifier-free guidance
- –ddim_steps:如果为正,则执行 ddim 的步骤,否则使用 DDPM。
- –ddim_eta:ddim 采样的 eta(0.0 产生确定性采样)
- –video:视频路径
总结
官方的展示还挺多的,但是占用空间较大,站长的破服务器为了减轻负担,还是不折腾上来了吧。
这个项目玩玩还可以,但是做为生产力,还很遥远。


站长,这个显存大小有没有要求?