
Stable Diffusion|图像生成的工作原理
Stable Diffusion的项目开源地址:https://github.com/CompVis/stable-diffusion
技术交流
本站已开放AI技术交流论坛,如果您在学习过程当中遇到问题,可在本站论坛【点击前往】发帖求助。
极速版
Stable Diffusion的工作原理用人类可以理解的方式来说,其实就是两个过程。
训练过程
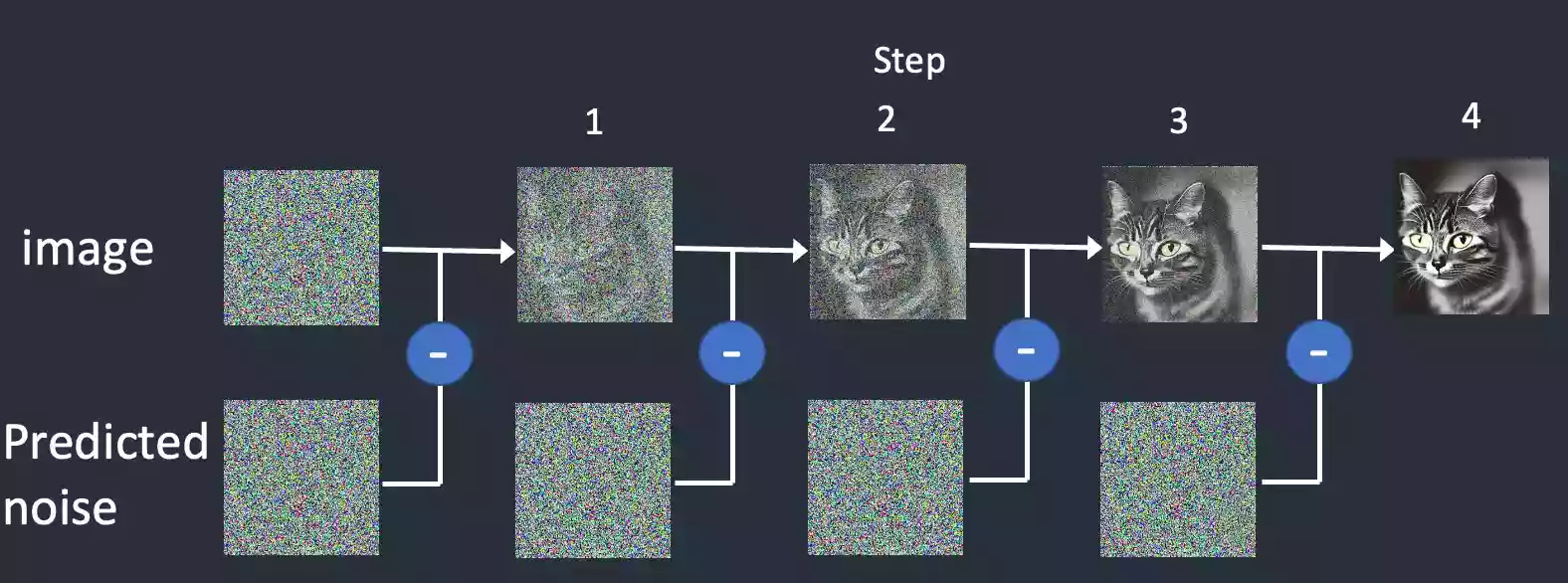
Stable Diffusion的训练过程其实就是在一张图片上逐渐添加噪点,最后完全变成一张类似完全黑白的噪点图像,AI将会记录每一步的噪点特征。

生成过程
AI通过训练时的噪点学习记录,去根据噪点逐渐生成你想要的图像进行还原。
不学习此部分内容不会对你使用AI进行绘画有任何影响,如果你想深究AI绘画的原理,那么可以继续观看如下内容,否则可跳过该部分。
训练介绍
中文直译为:稳定的扩散
它是如何工作的呢?Stable diffusion是一中潜在扩散模型(latent diffusion model),这里面除了模型这两个字,潜在和扩散听上去可能不太容易理解,这里我们先弄明白什么是扩散模型,它是在训练图像上逐渐添加噪声,最后变成完全随机噪声图。这个过程就像是一滴墨水滴在一杯清水里,会慢慢扩散最终均匀分布在清水里一样,扩散这个名字就是那么来的。
这是一个前向扩散的过程,因为让一张图片越来越模糊没什么技术含量。
而扩散模型就是通过训练让上述过程获得逆向从随机噪声图生成清晰图像的过程。训练的重点就是下图中的噪声预测器(noise predictor),它可以通过训练得出每次需要减掉的噪声,每次需要减多少噪声是预测出来的,从而实现还原清晰图片的目的。
简单地说,扩散模型的工作原理是通过连续添加高斯噪声来破坏训练数据,然后学习通过反转这种噪声过程来恢复数据。
扩散过程,从字面上理解就是,像分子运动一样,一点点改变(放到图像里就是,最开始噪声一般的图像,它的像素值一点点改变,或者说叫”运动”,直到最后改变成了有意义的图像)。
扩散模型(diffusion model)
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain)。
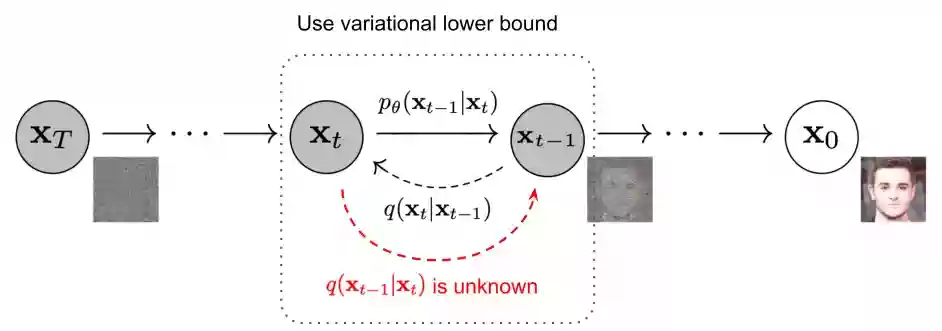

扩散模型由两部分构成:学习过程,推理过程,上面的去噪过程就是推理过程。
学习过程
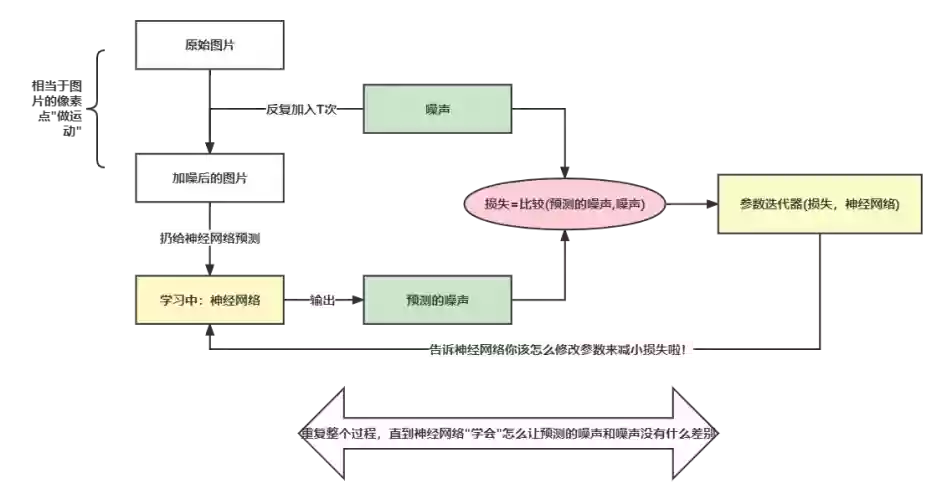
- 首先我们拿到要学习的图片I。
- 然后用固定的方法添加一个噪声 N ,并把这个噪声 N 保存下来。
- 把噪声 N 扔给我们的神经网络,神经网络会返回一个同尺寸的噪声 PN。
- 比较神经网络预测的噪声 PN 和 N 数学尺度上的”差距” ,这个差距我们记为 D。
- 把这个差距 D 扔给一个迭代器,它会告诉神经网络应该怎么调整它里面众多的神经参数来缩小 N 和 PN的差距。
- 最后重复不断这个过程,直到 D 的值足够小。
推理过程
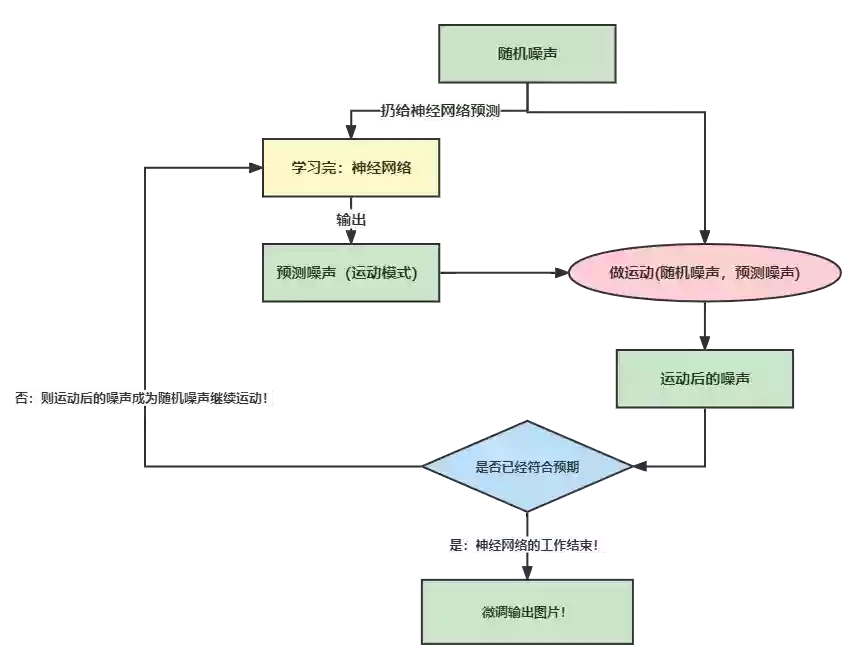
- 首先我们随机生成一个噪声 RD。
- 把 RD 喂给已经学习好的 神经网络。
- 得到神经网络给出的噪声 PD。
- 用原始的噪声 RD根据 PD做运动,得到预测的图片I。这里的运动可以简单理解为原始噪声RD的数值减去预测噪声PD。实际上是做了一些数学变化,而非简单的加减。
- 判断做完运动得到的预测I是否符合我们的预期,如果符合,那就完成预测啦!否则继续6。
- 如果运动还不够,则刚刚得到的预测图片I成为新的噪声RD,进行下一轮运动,直到得到我们需要的图片。
❗ 注意:我们到目前为止描述的扩散过程在不使用任何文本数据的情况下生成图像。因此,如果我们部署这个模型,它将生成漂亮的图像,但我们无法控制它是金字塔还是猫或其他任何东西的图像。

如何控制扩散
人类绘画过程
要了解文生图怎么做到的,我们先看一下人类通常的作画流程,当人类开始进行艺术创作时,拿绘画举例,我们通常大致可以归类为以下几个步骤:
- 确立主题:这一阶段,我们会收集绘画想表达的内容,中心思想,或者说绘画本身的目的,再具体的说,这一阶段我们会去和绘画的需求方确认创作的这幅画的尺寸,主题,背景,需求方的目的,应用的场景等等。
- 细化需求:确立了主题,接下来就是细化需求,这一阶段我们可能需要收集内容的相关的素材,相关的文化知识,背景信息,画风等等来辅助我们创作。
- 绘制草稿:细化了需求,接下来可能会找一些参考图,进行一些草图,线稿,素描等创作。
- 完成绘图:最后,在草稿的基础上根据需求完成整体的构图,绘画,最终交付。

diffusion model在生成图片时需要指引,我们可以通过图片/文字进行实现
我们如何用语言来指引或控制最后生成的结果?
答案也很简单——注意力机制。在最开始我们讲到,我们用Text Encoder提取语义信息。
那这个语义信息怎么在生成图片的过程中使用呢?我们直接使用注意力机制在Unet内层层耦合。
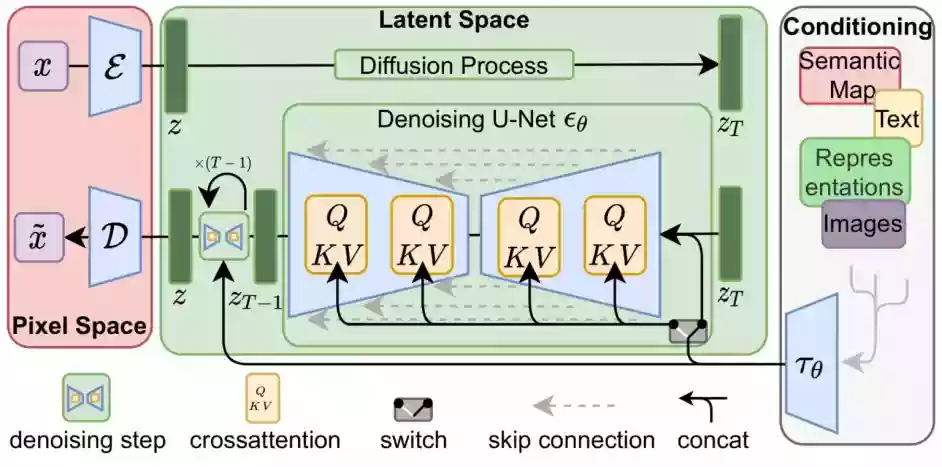
图中每个黄色的小方块都代表一次注意力机制的使用,而每次使用注意力机制,就发生了一次图片信息和语义信息的耦合
文本编码器:A Transformer Language Model
自从2018年Bert发布以来,Transformer的语言模型就成了主流。Stable Diffusion起初的版本便是用的基于GPT的CLIP模型,而最近的2.x版本换成了更新更好的OpenCLIP,最近也有学者试图将Chatgpt模型与Stable Diffusion进行结合。语言模型的选择直接决定了语义信息的优良与否,而语义信息的好坏又会影响到最后图片的多样性和可控性。
Google在Imagen论文中做过实验,可以发现不同语言模型对生成结果的影响是相当大的。
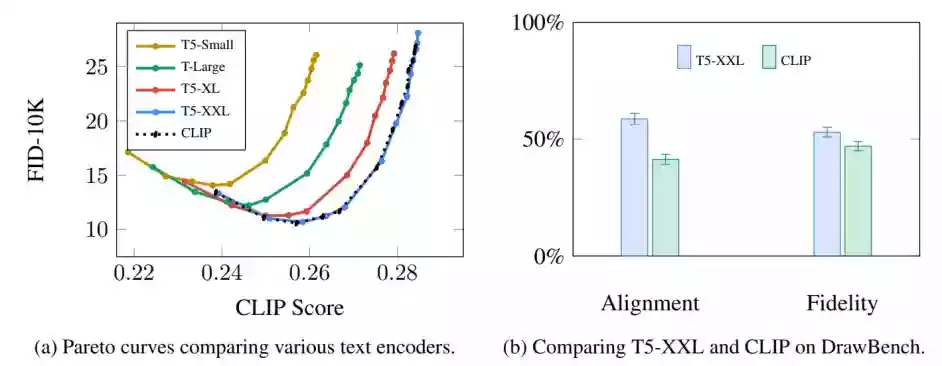
更大/更好的语言模型对图像生成模型的质量有显著影响。
Clip如何训练
那像CLIP这样的语言模型究竟是怎么训练出来的呢?它们是怎么样做到结合人类语言和计算机视觉的呢?
首先,要训练一个结合人类语言和计算机视觉的模型,我们就必须有一个结合人类语言和计算机视觉的数据集。CLIP就是在像下面这样的数据集上训练的,只不过图片数据达到了4亿张的量级。事实上,这些数据都是从网上爬取下来的,同时被爬取下来的还有它们的标签或者注释。
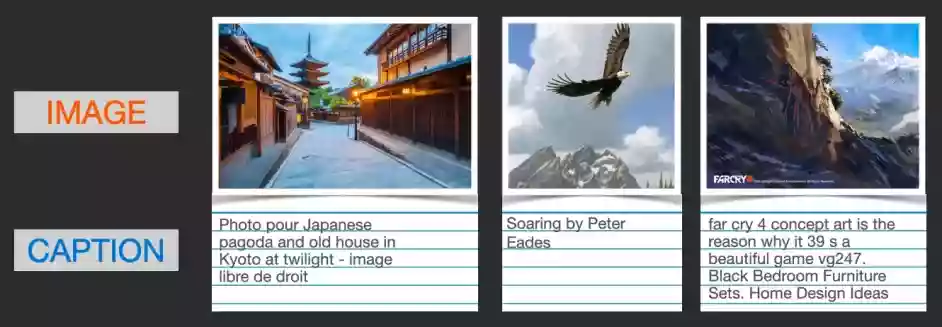
CLIP模型包含一个图片Encoder和一个文字Encoder。训练过程可以这么理解:我们先从训练集中随机取出一张图片和一段文字。注意,文字和图片未必是匹配的,CLIP模型的任务就是预测图文是否匹配,从而展开训练。
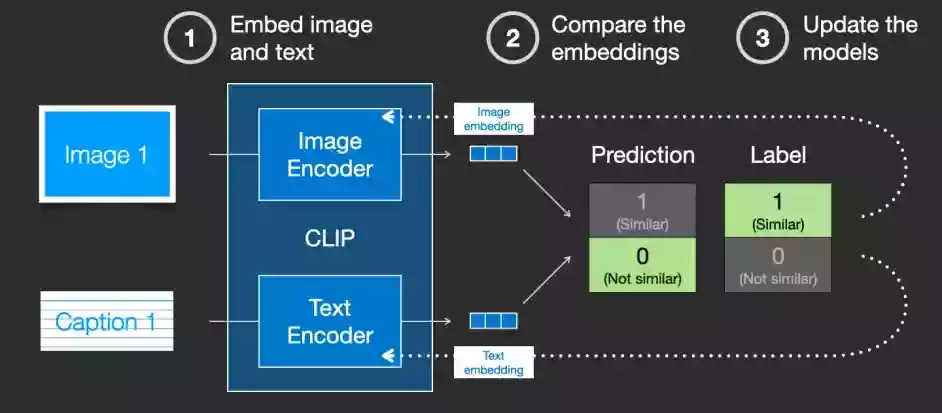
CLIP 包含一个图像编码器(Image Encoder)和一个文本编码器(Image Encoder)
- 我们分别用俩个编码器对图像和文本进行编码,输出结果是俩个embedding向量。
- 我们用余弦相似度来比较俩个embedding向量相似性,以判断我们随机抽取的文字和图片是否匹配。但最开始,由于两个编码器刚刚初始化,计算出来的相似度往往会接近于0。
- 这时候假设我们模型的预测是 Not similar 而标签为Similar ,那么我们的模型就会根据标签去反向更新俩个编码器。
不断地重复这个反向传播的过程,我们就能够训练好两个编码器,来识别图像和文本的匹配程度。
值得注意的是,就像经典的word2vec训练时一样,训练CLIP时不仅仅要选择匹配的图文来训练,还要适当选择完全不匹配的图文给机器识别,作为负样本来平衡正样本的数量。
利用Clip
粉色的Unet中每个Resnet不再和相邻的Resnet直接连接,而是在中间新增了Attention的模块。CLIP Encoder得到的语义embedding就用这个Attention模块来处理。
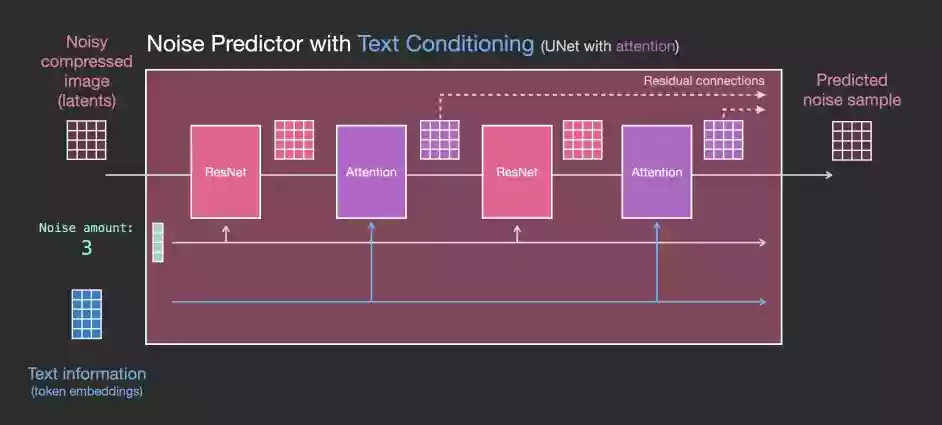
整个Unet是由一系列Resnet构成的,每一层的输入都是上一层的输出。
从宏观的视角来看
在图片信息生成器(Image Information Creator)中,有了初始的纯噪声【下图中左下透明4X4】+语义向量【下图左上蓝色3X5】后,Unet会结合语义向量不断的去除纯噪声隐变量中的噪声,重复50~100次左右就完全去除了噪声。

得益于Clip的强大,我们可以不仅可以以类标签的文本生成图像,也能通过一些英语短句来生成图像
比如:”树下有一个女孩身边有一条狗(a girl with a dog under a tree)“

到这里我们就对stable diffusion原理有了大概了解。
点击下文前往Stable Diffusion的教程总目录,学习其它内容。
此文章参考以下内容整理
stable diffusion webui如何工作以及采样方法的对比



蟹蟹,通俗易懂
通俗易懂