
SInfinite Zoom|视频画面无限缩放插件
之前本站已经讲过了根据视频生成动画风格转换,那么如果没有视频呢?本次将会将大家如果无限放大或缩小某张图片,使其达到一定的幻觉效果,期间还可以实时调整画面内容Prompt提示词。
本站认为Infinite Zoom生成后的效果很一般,所以本插件并没有详细的去讲解,可主要功能也基本部分都讲解了。
插件安装
插件已被内置在Stable Diffusion WebUI的扩展内,我们直接输入Infinite zoom,然后点击安装按钮即可。
安装完成后,重载前端UI,此时将会在Stable Diffusion WebUI的UI界面内看到Infinite Zoom选项卡,界面如下。
模型推荐
本插件推荐使用以下模型,这些模型具有更好的衔接效果,可以有效避免生成后的视频存在接缝的问题。
- StableDiffusion-v2-inpainting
- StableDiffusion-v1.5-inpainting
- Delibrate-inpainting
- RealisticVision-inpainting-v2.0
- DreamShaper-inpainting-v4
- ReV-Animated-inpainting-v1.1
本次本站所使用的演示模型为ReV Animated,如有需要,有点击前往【本站论坛】下载。
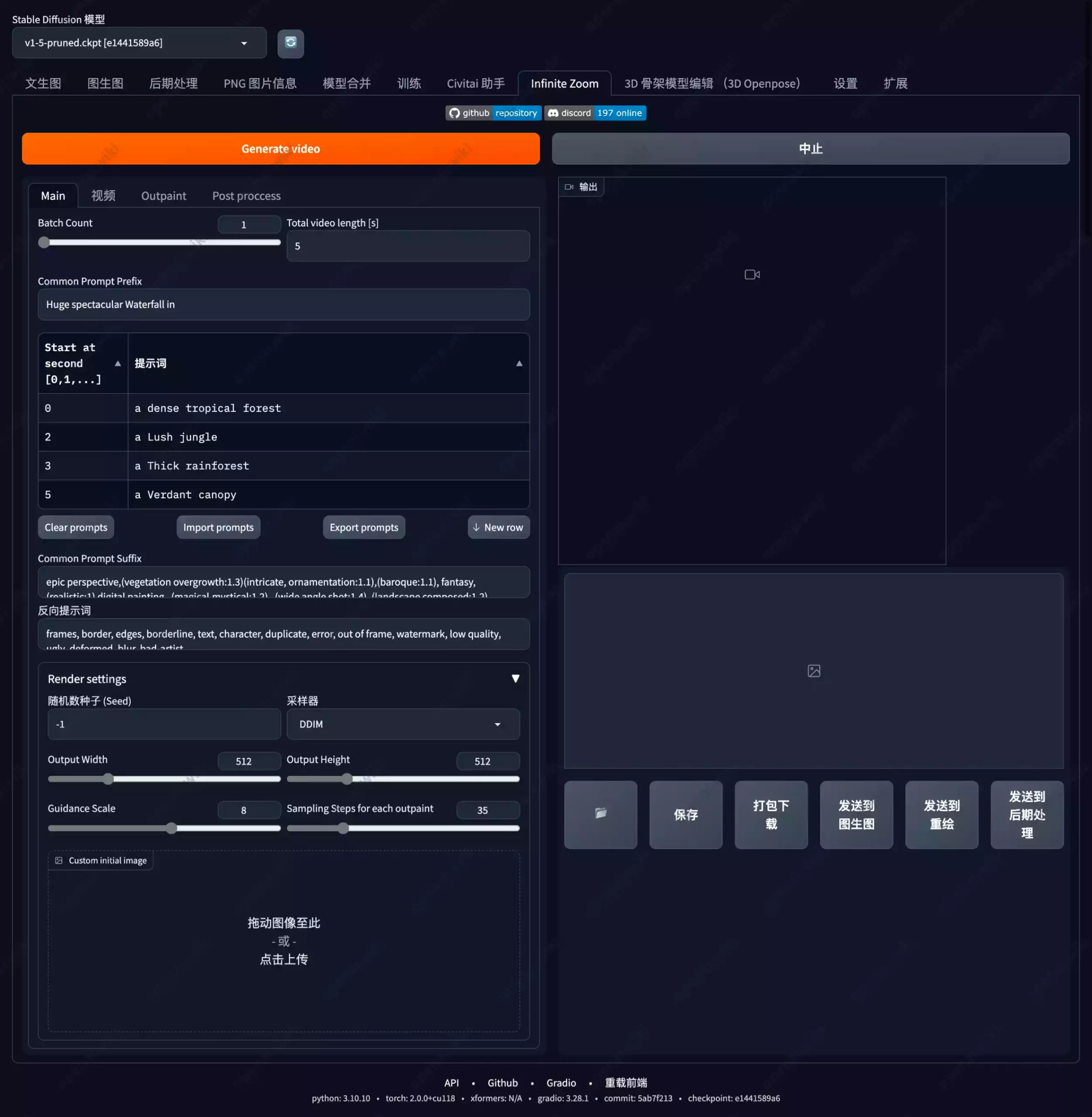
主界面功能介绍
为方便大家理解,本站大概翻译了一下界面的各按钮名称。
通过Prompt前缀
该部分的内容是指,无论你所生成的哪一个画面,都将会在你的Prompt提示词的起始部分使用如下内容,默认给出的案例是巨大壮观的瀑布。

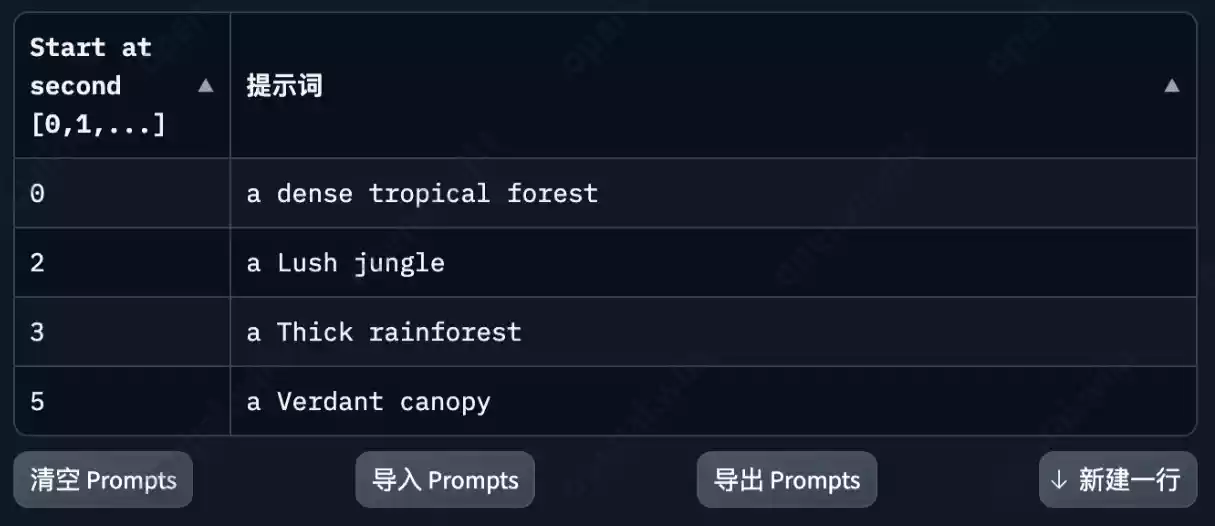
Prompt/秒
此部分内容的左侧数字是指第几秒生成的内容,比如画面中的第0秒图像为茂密的热带森林,第2秒图像为郁郁葱葱的丛林,第3秒图像为茂密的热带雨林,第5秒图像为翠绿的树冠,中间会自动过度。
如果你对当前每秒提示词比较满意,可以导出或导入当前Prompt。如果你想添加更多内容,也支持再新建一行。
通用Prompt
该部分与正常的文生图Prompt提示词功能相同,也就是生成每一张图像是,自动添加在最后的通用Prompt。
关于反向Prompt是全部画面通用的,无法单独修改。
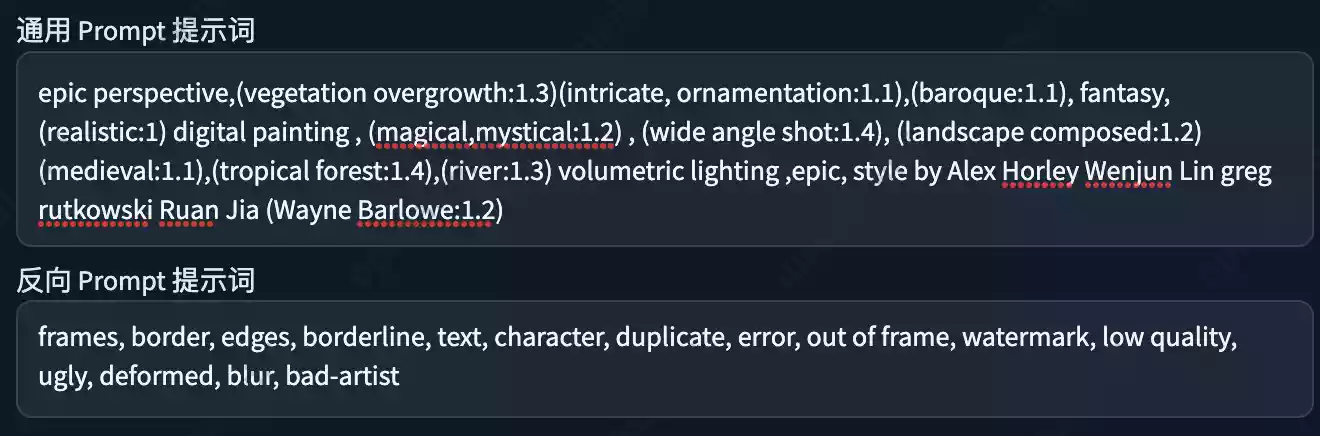
Prompt解析
我们已经理解了这些Prompt的作用,结合以上内容,举例一下。
在生成第一张图像时,将会自动组合这三部分内容。使用通过Prompt前缀+0秒提示词+通用Prompt提示词,反向Prompt就是不想生成的内容,不做单独讲解了。
通过以上组合,那么第0秒生成图像的完整正向提示词为以下内容。
Huge spectacular Waterfall in,a dense tropical forest,epic perspective,(vegetation overgrowth:1.3)(intricate, ornamentation:1.1),(baroque:1.1), fantasy, (realistic:1) digital painting , (magical,mystical:1.2) , (wide angle shot:1.4), (landscape composed:1.2)(medieval:1.1),(tropical forest:1.4),(river:1.3) volumetric lighting ,epic, style by Alex Horley Wenjun Lin greg rutkowski Ruan Jia (Wayne Barlowe:1.2)
第2秒生成图像的完整正向提示词为以下内容。
Huge spectacular Waterfall in,a Lush jungle,epic perspective,(vegetation overgrowth:1.3)(intricate, ornamentation:1.1),(baroque:1.1), fantasy, (realistic:1) digital painting , (magical,mystical:1.2) , (wide angle shot:1.4), (landscape composed:1.2)(medieval:1.1),(tropical forest:1.4),(river:1.3) volumetric lighting ,epic, style by Alex Horley Wenjun Lin greg rutkowski Ruan Jia (Wayne Barlowe:1.2)
每一张图像的完整反向提示词为以下内容。
frames, border, edges, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur, bad-artist
后面的逻辑几乎一致,不做单独讲解。
随机数种子
如果该参数为固定的,那么生成的内容将会完全一致,这就失去了意义,所以建议为-1,不做任何变动。
初始化图像
在主功能界面的最下方,有一个Custom initial image区域,我们可以上传一张图像做为初始化图像,也就是第一张图像是可以不通过生成,而手动指定的。

视频参数
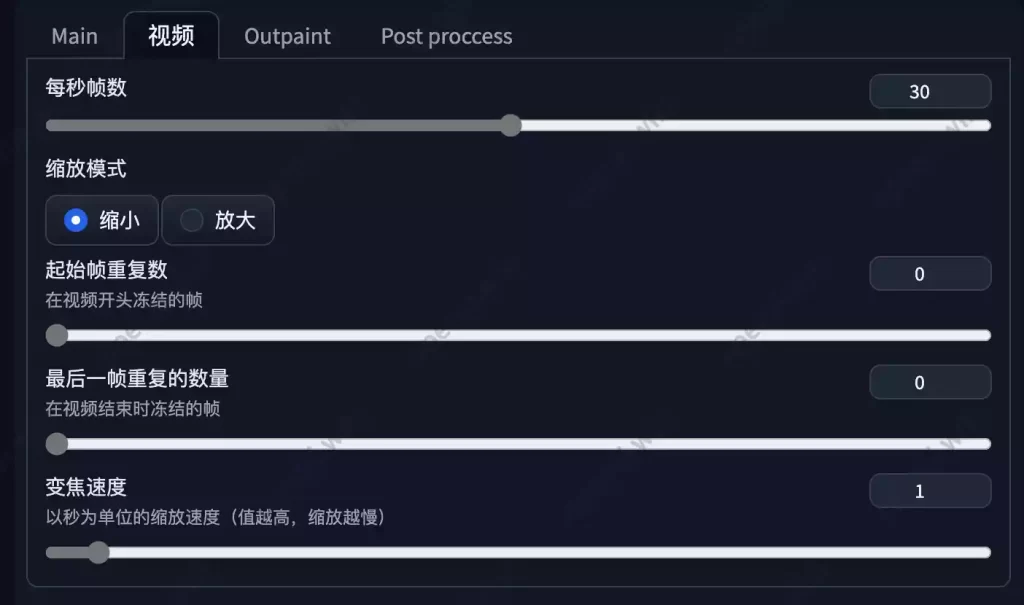
- 每秒帧数
- 关于帧的理解,这个解释起来可能不是特别容易理解。视频是如何动起来的呢,其实每一秒视频是由很多张图片来组合而成的,有点像在快速翻书的效果,至于一秒之内一共翻了多少页,就代表这个视频是多少帧,目前主流的为
24帧、25帧、30帧、60帧。我们以30帧为例,也就是代表该视频每秒由30图片所组成。 - 组成视频的这些图像如果被拆解成一张张图片,那就是一个个帧。如果这些帧的序号是连续的,那就可以称之为序列帧,我们本节通过生成多张连续的序列帧来生成动画视频。
- 简而言之,如果你不知道这是什么,填写
30就可以啦。
- 关于帧的理解,这个解释起来可能不是特别容易理解。视频是如何动起来的呢,其实每一秒视频是由很多张图片来组合而成的,有点像在快速翻书的效果,至于一秒之内一共翻了多少页,就代表这个视频是多少帧,目前主流的为
- 缩放模式
- 缩小
- 是指画面的中心逐渐缩小,显示出更大范围填充区域的视频。
- 放大
- 是指画面由远及近,逐渐从远处放大至某一个点,有点像镜头高倍变焦的效果。
- 缩小
- 起始帧重复数
- 可以理解为第一帧的定格帧数量
- 最后一帧重复的数量
- 最后一帧的停留时间
- 变焦速度
- 放大或缩小的变焦速度
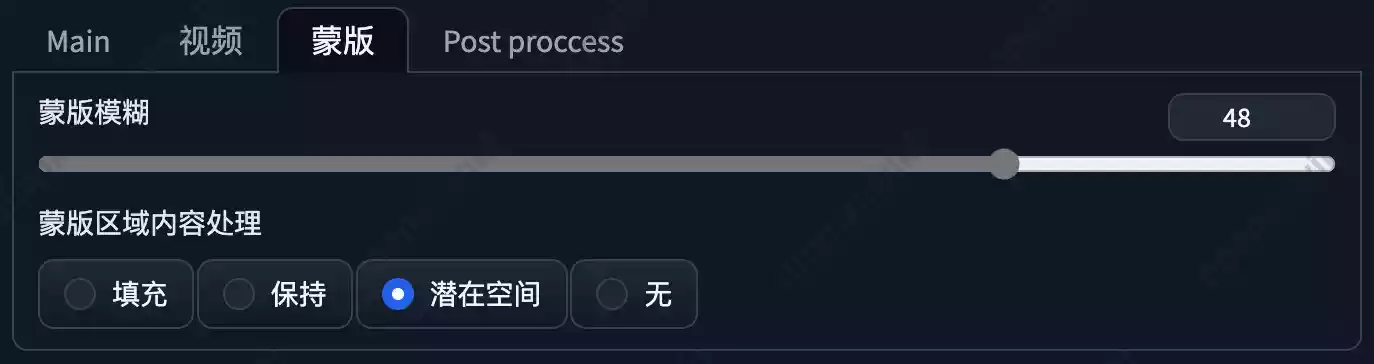
蒙版
该部分的内容是用来调整每个画面的边缘模糊效果,如果模糊值过小,那么边缘会非常生硬,没有过度,一般保持默认即可。
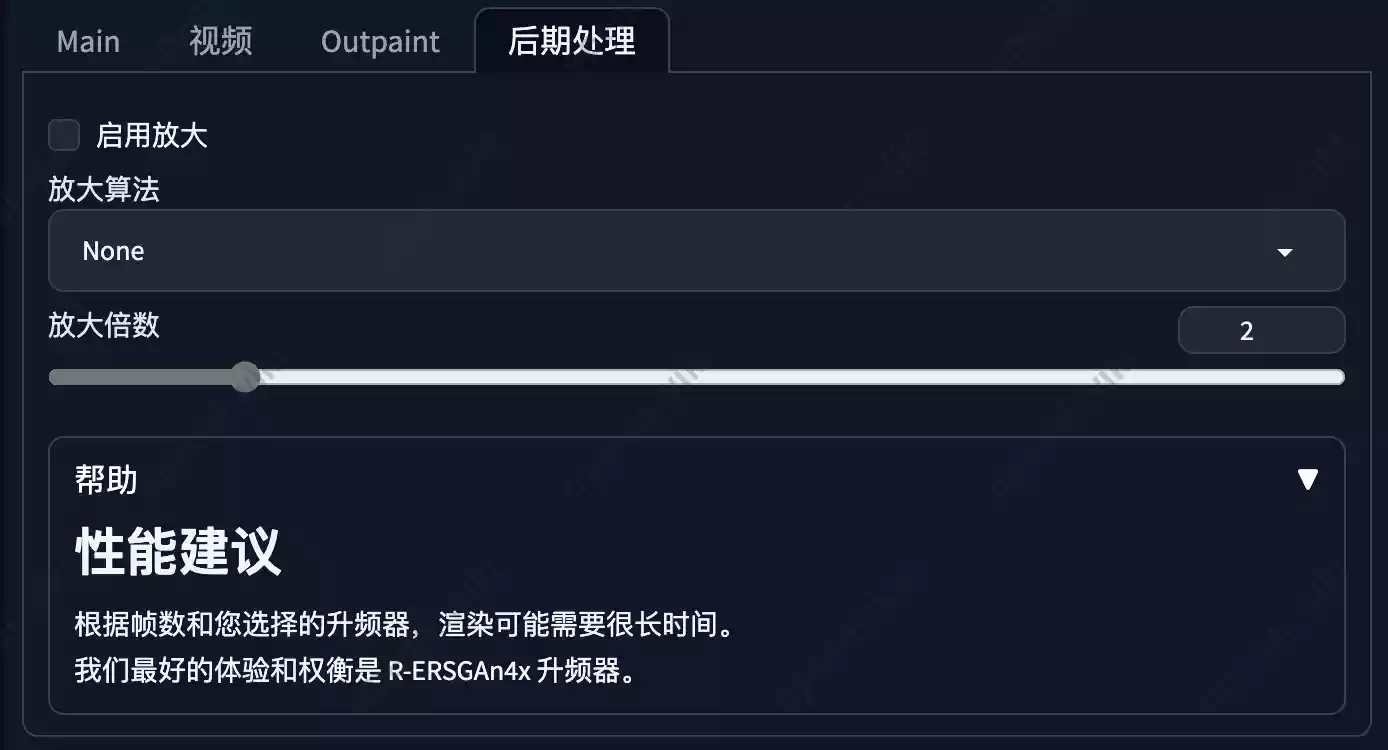
后期处理
如果你生成的视频非常模糊且不清晰,那么可以选择勾选启用放大功能,然后选择一个算法,官方推荐使用R-ESRGAN 4x+算法。
效果展示
不知道是不是我的问题,但是效果真的就是很一般。
被盗用的文章太多太多了,我们不求打赏,也不求广告收益,我只求各位大佬在转载的时候可以保留出处,谢谢。



评论 (0)