
聚类嵌入
本文展示了如何使用简单的K-means算法进行聚类。聚类可以帮助在数据中发现有价值的、隐藏的分组。本例中使用的数据集在 Obtain_dataset Notebook 中创建。
正文
我们使用简单的 k-means 算法来演示如何进行聚类。 聚类可以帮助发现数据中有价值的、隐藏的分组。 数据集在 Obtain_dataset Notebook 中创建。
# imports import numpy as np import pandas as pd # load data datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv" df = pd.read_csv(datafile_path) df["embedding"] = df.embedding.apply(eval).apply(np.array) # convert string to numpy array matrix = np.vstack(df.embedding.values) matrix.shape
(1000, 1536)
1.使用 K-means 找到聚类
我们展示了 K-means 的最简单用法。 您可以选择最适合您的用例的集群数量。
from sklearn.cluster import KMeans
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["Cluster"] = labels
df.groupby("Cluster").Score.mean().sort_values()
/Users/ted/.virtualenvs/openai/lib/python3.9/site-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning warnings.warn(
Cluster 0 4.105691 1 4.191176 2 4.215613 3 4.306590 Name: Score, dtype: float64
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
for category, color in enumerate(["purple", "green", "red", "blue"]):
xs = np.array(x)[df.Cluster == category]
ys = np.array(y)[df.Cluster == category]
plt.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
plt.title("Clusters identified visualized in language 2d using t-SNE")
Text(0.5, 1.0, 'Clusters identified visualized in language 2d using t-SNE')
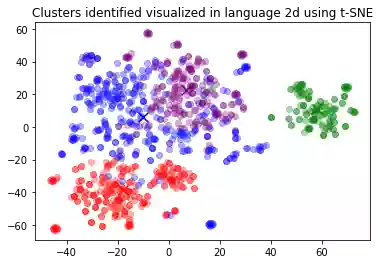
二维投影中簇的可视化。 在此运行中,绿色集群 (#1) 似乎与其他集群完全不同。 让我们看看每个集群的一些样本。
2.集群中的文本样本和集群命名
让我们展示来自每个集群的随机样本。 我们将使用 text-davinci-003 来命名集群,基于来自该集群的 5 条评论的随机样本。
import openai
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response["choices"][0]["text"].replace("\n", ""))
sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])
print("-" * 100)
聚类 0 主题:所有评论都是正面的,客户对他们购买的产品感到满意。
5,喜欢这些不含麸质的健康棒,在亚马逊上节省了 $$ 的订购费用:这些 Kind Bars 非常好、健康且不含麸质。 我的女儿
1,应该更突出地宣传椰子作为一种成分:首先,这些应该称为 Mac – 椰子棒,因为椰子是 #2
5, 非常好!!: 和runts一样
味道好极了,绝对值得入手
我什至
5、极品:找遍镇上每家店都没有找到橙皮
5、好吃:青蛙软糖是我吃过最喜欢的糖果。 的
集群 1 主题:所有评论都是关于宠物食品的。
2,凌乱且明显不好吃:我的猫不是超级粉丝。 当然,她会舔肉汁,但留下
4,猫喜欢它:我的7只猫喜欢这种食物,但对人类来说有点难吃。 片
5, cant get enough of it!!!:我们的 lil shih tzu 小狗总是吃不够。 每次她看到
1,食物引起的疾病:我把我的猫从 Blue Buffalo Wildnerness Food 换成了这个
5,我的毛茸茸的宝宝喜欢这些!:摇晃容器,它们就会跑起来。 甚至我的男孩猫,谁不是
集群 2 主题:所有评论都是正面的,并对产品表示满意。
5、追雾咖啡:这款咖啡酒体饱满,口感丰富。 价格远低于吨
5、极佳的口感:这对我来说是一款很棒的咖啡,一旦你尝试就会喜欢它,这
4,好,但不是 Wolfgang Puck 好:老实说,我不得不承认我期望好一点。 那不是
5、Just My Kind of Coffee:Coffee Masters Hazelnut coffee 曾经在当地的咖啡店/pa
5、Rodeo Drive is Crazy Good Coffee!:Rodeo Drive 绝对是我的最爱,我准备多点一些! 那
第 3 组主题:所有评论都与食品或饮料产品有关。
5、汽水的绝佳替代品:这是汽水的绝佳替代品。 它是碳酸的
5、太方便了,花这么少!:我老公做的爱情女神蛋糕需要两颗香草豆
2,机器人非常俗气:大约一个月前得到这个。首先它闻起来很难闻……味道
5,美味!:我不是啤酒爱好者。 我确实喜欢偶尔的蓝月亮(所有 o
3,还行:我买这个牌子是因为我们附近的Ranch 99他们只有这个牌子。 我
请务必注意,集群不一定与您打算使用它们的用途相匹配。 大量的聚类将关注更具体的模式,而少量的聚类通常会关注数据中最大的差异。


评论 (0)