
CUDA
CUDA(Compute Unified Device Architecture)是由英伟达(Nvidia)开发的高性能并行计算架构。它是一种用于开发高性能计算应用程序的编程模型,可以更有效地利用Nvidia的GPU(图形处理单元)的计算能力。
CUDA为开发人员提供了一种方便的方法,通过并行编程来加速复杂的计算任务。它提供了丰富的API,以便在GPU上运行并行任务,并通过GPU和CPU之间的数据传输来加速整个系统的性能。
CUDA支持各种编程语言,包括C、C++、Fortran、Python等,并且可以与常见的科学计算、机器学习和人工智能框架(如TensorFlow)无缝集成。
CUDA的应用非常广泛,主要用于高性能计算、图像处理、机器学习、生物信息学、石油勘探等领域。它可以帮助开发人员提高计算效率,降低计算成本,并加速科学研究和工程设计的进展。
总的来说,CUDA是一种高效、易用的并行计算架构,为计算密集型应用程序提供了极大的性能优势。
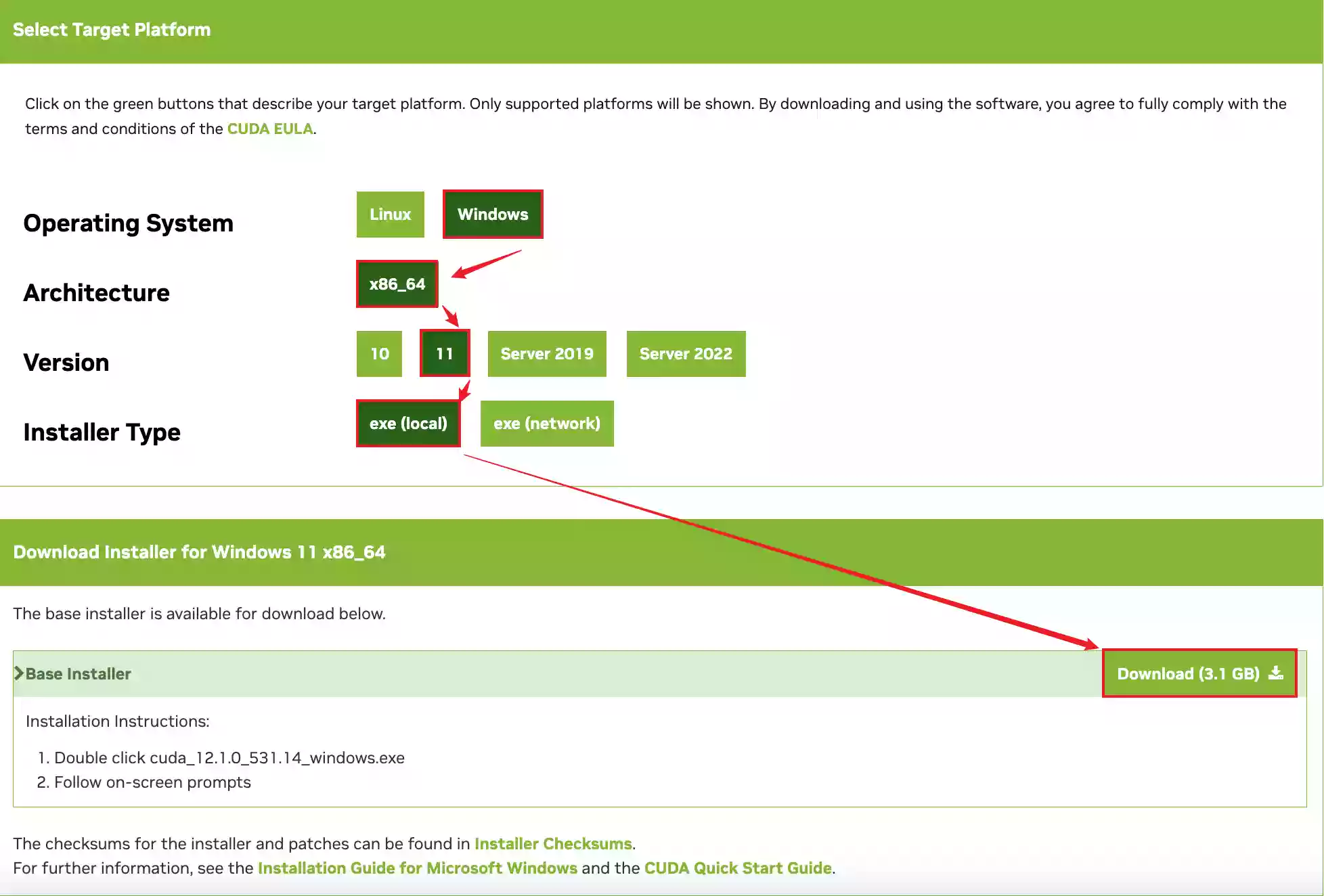
下载地址
安装教程
相关描述
下面是关于使用CUDA进行开发以及编程的示例,如果您只是使用者,仅观看上面的安装教程即可。
CUDA(Compute Unified Device Architecture)是一种由NVIDIA开发的并行计算平台和编程模型,用于在NVIDIA GPU(图形处理器)上进行高性能计算。CUDA支持C、C++、Python和Fortran等编程语言,并且可以在Windows、Linux和macOS等多个操作系统上运行。
使用CUDA进行高性能计算可以极大地加速计算过程,特别是对于那些需要大量并行计算的应用程序。例如,在科学计算、人工智能、机器学习和深度学习等领域中,CUDA可以显著提高计算速度。
以下是使用CUDA进行高性能计算的一般步骤:
- 安装CUDA:
首先,您需要从NVIDIA官网下载并安装适用于您的GPU的CUDA工具包和驱动程序。CUDA工具包包括CUDA编译器、CUDA运行时库和CUDA开发工具包等。 - 编写CUDA程序:
使用CUDA编程模型编写程序。CUDA编程模型基于主机和设备之间的分离,其中主机指CPU,设备指GPU。主机代码在CPU上运行,设备代码在GPU上运行。 - 分配GPU内存:
在主机端为GPU分配内存,将数据传输到GPU上。 - 执行CUDA核函数:
编写CUDA核函数,将其加载到GPU上执行。 - 从GPU读回数据:
将计算结果从GPU内存读回到主机内存中,以便进一步处理或输出。
下面是一个简单的CUDA程序示例,它使用CUDA对两个向量进行向量加法:
#include <stdio.h>
__global__ void vectorAdd(int *a, int *b, int *c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
int n = 1000;
int *a, *b, *c;
int size = n * sizeof(int);
cudaMalloc(&a, size);
cudaMalloc(&b, size);
cudaMalloc(&c, size);
for (int i = 0; i < n; i++) {
a[i] = i;
b[i] = 2 * i;
}
int blockSize = 256;
int numBlocks = (n + blockSize - 1) / blockSize;
vectorAdd<<<numBlocks, blockSize>>>(a, b, c, n);
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
在此示例中,向量加法的核函数 vectorAdd 在GPU上执行,使用 <<>> 表示执行的线程块数和每个线程块的线程数。在主机端,为向量 a、b 和 c 分配内存,并使用 cudaMalloc 函数在GPU上为其分配内存。然后,将数据从主机传输到GPU上,并执行核函数。最后,将计算结果传输回主机,并释放GPU内存。
总之,使用CUDA进行高性能计算需要一些GPU编程的知识,但是一旦掌握了基本概念和技能,就可以在GPU上实现高效的并行计算。以下是一些学习CUDA编程的资源:
- NVIDIA官方文档:NVIDIA官方网站提供了丰富的文档和教程,包括CUDA编程指南、CUDA C++开发指南、CUDA工具包文档等。
- Udacity课程:Udacity提供了免费的CUDA编程课程,包括基本概念、并行算法、性能优化等。
- Coursera课程:Coursera上也有许多与CUDA相关的课程,涵盖了从基本概念到实际应用的多个方面。
- GitHub示例:在GitHub上有许多开源的CUDA示例代码,可以帮助您了解实际的CUDA编程应用。
总之,CUDA是一种用于高性能计算的强大工具,可以加速许多需要大量并行计算的应用程序。通过学习CUDA编程,您可以充分利用现代GPU的强大性能,实现更快、更高效的计算。


评论 (0)